Ответы на вопросы по дисциплине «Прикладная эконометрика»
преподаватель – Черняк Владимир Ильич, 2010 год
ЧАСТЬ ПЕРВАЯ. ДО КОНТРОЛЬНОЙ.
ТЕМА 1. Метод наименьших квадратов. Свойства коэффициентов регрессии.
1. Что такое ковариация?
Ковариация – мера взаимосвязи между двумя переменными. Cov(x,y)=E[(x-μx)(y-μy)]. Ковариация в оценке силы связи между переменными не так полезна, как корреляция.
2. Что выражает ковариация переменных в регрессионной модели?
Зависимость или независимость переменных модели.
3. Каковы основные этапы построения и анализа регрессионной модели?
• Выдвижение рабочей гипотезы
• Построение модели
• Анализ качества и интерпретация модели
• Определение путей изменения модели
• Выдвижение новых гипотез и построение новых моделей.
• Практическое использование модели
4. В чем роль теоретической (гипотетической) регрессии в прикладном эконометрическом анализе?
Теоретическая (гипотетическая) регрессия позволяет производить теоретические расчеты (имеется в виду оценка последствий изменений значения какой-то объясняющей переменной), а также она используется для прогнозирования значений зависимой переменной.
Теоретическая регрессия:
Y=a+b*x+u, где u – случайный член
В регрессионном анализе изучается связь и
определяется количественная зависимость между зависимой переменной и одной или
несколькими независимыми переменными. Пусть переменная Y зависит от
одной переменной ![]() . При
этом предполагается, что переменная
. При
этом предполагается, что переменная ![]() принимает заданные фиксированные
значения, а зависимая переменна Y имеет случайный разброс из-за ошибок
измерения, влияния неучтенных факторов и т.д. Предположим, что Y в
"среднем" линейно зависит от значений переменной
принимает заданные фиксированные
значения, а зависимая переменна Y имеет случайный разброс из-за ошибок
измерения, влияния неучтенных факторов и т.д. Предположим, что Y в
"среднем" линейно зависит от значений переменной ![]() .
.
Таким образом, существуют наблюдаемые значения х и у, между ними предполагается линейная связь. Если бы соотношение между х и у было точно, то все наблюдаемые точки лежали на одной прямой Y=a+b*x. Однако истинные значения у отклоняются от этой прямой на величину случайного члена.
Таким образом, теоретическая регрессия необходима для оценки взаимосвязи между переменными. На основе n наблюдений строится расчетная регрессия, оцениваются коэффициенты а и b.
5. Почему расчетная регрессия не совпадает с теоретической?
Из-за наличия случайного члена невозможно рассчитать истинные значения b,α при попытке построить прямую и определить положение линии регрессии. т.к. остатки не совпадают со значениями случайного члена
6. В чем состоит разница между случайном членом
регрессии и остатками в регрессионном анализе?
Случайный член указывает на то, что существует случайная составляющая, которая влияет на зависимую переменную; остаток- измеренная величина отклонения между фактическим и расчетным значением переменной.
Случайный член (ui) включается в регрессию для подтверждения существования случайного фактора, оказывающего влияние на зависимую переменную. Yi=β1+β2Xi+ui
Остаток (ei) – измеримая разность между
действительной величиной Y в соответствующем наблюдении и расчетным
значением по регрессии. ei=Yi-![]()
7. В чем состоит идея метода наименьших квадратов?
Идея МНК основана на том, чтобы минимизировать сумму квадратов отклонений расчетных значений от эмпирических, т.е. нужно оценить параметры о функции f(a,x) таким образом, чтобы ошибки еi= уi-f(а,х), точнее - их квадраты, по совокупности были минимальными. Для этого нужно решить задачу минимизации суммы квадратов остатков S=e12+..+en2
8. В чем состоят основные достоинства и недостатки метода наименьших квадратов с точки зрения прикладной эконометрики?
Достоинства:
1. Наиболее простой метод выбора значений b1 и b2, чтобы остатки были минимальными;
2. При выполнении условий Гаусса-Маркова МНК-оценки будут наилучшими (наиболее эффективными) линейными (комбинации Yi) несмещёнными оценками параметров регрессии (b1 и b2).
Условия Гаусса-Маркова:
- модель линейна по параметрам и правильно специфицирована;
- объясняющая переменная в выборке имеет некоторую вариацию;
- математическое ожидание случайного члена равно нулю;
- случайный член гомоскедастичен;
- значения случайного члена имеют взаимно независимые распределения;
- случайный член имеет нормальное распределение
Недостатки: МНК-оценки являются эффективными линейными несмещёнными ТОЛЬКО при выполнении ВСЕХ условий Гаусса-Маркова, что на практике встречается редко.
9. Как получить уравнения метода наименьших квадратов, используя производные?
y=a+bx; S2=∑(yi-a-bxi)2=> (S2)a’=0 и (S2)b’=0
10. Как выписать уравнения метода наименьших квадратов, не используя производные?
![]()
![]()
11. Пусть выборка состоит из трех точек (x1, y1), (x2, y2), (x3, y3). Как вывести уравнения метода наименьших квадратов, используя условия первого порядка для производных.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
12. Как коэффициенты регрессии выражаются через основные статистические характеристики выборки (среднее, дисперсия, ковариацию и др.).
Вывод формул для оценки коэффициентов (для парной регрессии) в лекции 3.
![]()
![]()
13. Почему коэффициенты регрессии могут рассматриваться как случайные переменные? Каковы практические последствия этого факта?
Значения коэффициентов не могут быть точно предсказаны, находится их оценка (как частный случай). Коэффициент регрессии, вычисленный методом наименьших квадратов, - особая форма случайной величины, свойства которой зависят от свойств случайного члена в уравнении. Коэффициент регрессии, полученный по любой выборке, состоит из 2 слагаемых: 1) постоянной величины, равной истинному значению коэффициента, и 2) случайной составляющей, зависящей от случайного члена в выборке.
Последствия этого факта таковы, что возникает отклонение фактического значения от расчетного, в результате которого образуются остатки.
14. Что означает, что оценка коэффициента регрессии является несмещенной?
Математическое ожидание оценки равняется соответствующей характеристике генеральной совокупности.
15. Что означает, что оценка коэффициента регрессии является эффективной?
Она является надежной\точной с определенным уровнем значимости и чем он меньше, тем меньше вероятность ошибки (функция плотности вероятности распределения как можно более сжата вокруг истинного значения, т.е. дисперсия данной оценки минимальна). P-value низкий, что означает маленькую вероятность ошибки.
16. Что означает, что оценка коэффициента регрессии является состоятельной?
Это оценка, которая дает точное значение для большой выборки независимо от входящих в нее конкретных наблюдений, другими словами несет в себе меньшую среднеквадратичную ошибку.
17. Каковы свойства есть у остатков в парной регрессии? Запишите эти свойства в строгой математической форме?
eср=0, Cov(yоц.,e)=0, Var(ei)=const, Cov(ei,ej)=0. Свойства при МНК: ∑ei=0 и ∑Xiei=0
18. На какие компоненты раскладывается общая сумма квадратов остатков? В чем их смысл?
Общая сумма квадратов остатков (TSS) раскладывается на «объясненную» сумму квадратов (ESS) и остаточную («необъясненную») сумму квадратов (RSS).
TSS = ESS+ RSS
Подобное разложение позволяет оценить, на сколько хорошо выбранная модель (регрессия) объясняет поведение зависимой переменной. В частности, это используется при расчете коэффициента детерминации (R2). R2 показывает долю объясненной дисперсии зависимой переменной.
R2=ESS/TSS=1-RSS/TSS
19. Что такое коэффициент детерминации R2? Каков его смысл?
Коэффициент детерминации дает предварительную оценку качества модели и имеет значения в промежутке от 0 до 1. Он показывает долю объясненной дисперсии зависимой переменной (доля общей суммы квадратов, объясненной уравнением регрессии).
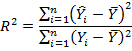
Если постоянный член включён в модель, то
разложение ![]() верно. Значит можно записать R2 следующим образом:
верно. Значит можно записать R2 следующим образом:
![]()
В иных случаях разложение неверно и уравнение расчёта R2 не эквивалентны.
R2=1, когда
линия регрессии точно соответствует всем наблюдениям, так что ![]() для всех наблюдений и все остатки
равны нулю. Можно сказать, что уравнение является идеальным. Если в выборке
отсутствует видимая связь между Y и
Х, то R2 будет близок к 0.
для всех наблюдений и все остатки
равны нулю. Можно сказать, что уравнение является идеальным. Если в выборке
отсутствует видимая связь между Y и
Х, то R2 будет близок к 0.
Коэффициент детерминации не позволяет дать окончательного заключения без учета других факторов, т.к. он подвержен влиянию посторонних факторов и может привести к ошибочному выводу. Даже если отсутствует зависимость между Y и Х, по любой данной выборке наблюдений может показаться, что такая зависимость существует, возможно, и слабая. Только по случайному стечению обстоятельств R2 в точности равен 0.
Однако таблицы для критических значений R2 отсутствуют, для этого нужно рассчитывать на его основе другие показатели. Например, F-критерий для проверки качества оценивания.
![]()
После вычисления F-критерия по значению коэффициента R2 отыскивается критический уровень F (Fкрит). Если F > Fкрит, то нулевая гипотеза (связь между Y и Х отсутствует) отклоняется и делается вывод, что имеющееся объяснение поведения Y лучше, чем можно было бы получить случайно.
Но возможен и расчет критического значения R2:
![]()
Если R2 > R2крит, то вывод об отклонении нулевой гипотезы подтверждается.
Согласие эмпирической прямой с данными, другими словами, показывает соответствие линии регрессии всем наблюдениям. Показывает наличие видимой/слабой связи между зависимой и объясняющими переменными, другими словами вклад переменной в модель. R2 показывает долю дисперсии зависимой переменной, “объясненной” (уравнением регрессии)
20. Какова связь коэффициента детерминации и коэффициента корреляции в парной
модели регрессии?
Чем больше R2, т.е., чем больше соответствие, обеспечиваемое уравнением регрессии, тем больше должен быть коэффициент корреляции для фактических и прогнозных значений у, и наоборот. R2 = коэффициент корреляции в квадрате.
21. Каковы пределы изменения коэффициента детерминации R2? Почему они такие?
0<R2<1, R2=1, когда уоц.=уi и все остатки равны 0 (Var(yоц.)=Var(y), Var(e)=0)
22. Почему метод наименьших квадратов эквивалентен задаче максимизации коэффициента детерминации R2?
![]() , а следовательно
, а следовательно ![]()
23. Какие практические выводы можно сделать из того факта, что коэффициент детерминации R2 оказался близок к единице?
1. Линия регрессии точно соответствует всем наблюдениям, отклонений нет
2. В оцениваемую модель не включили константу
3. Число объясняющих переменных равно (или близко) числу наблюдений
4. Сильная корреляция между переменными (нестационарность временных рядов)
24. Какие практические выводы можно сделать из того факта, что коэффициент
детерминации R2 оказался близок к нулю?
В выборке отсутствует видимая связь между зависимой и объясняющей переменной
25. Имеет ли смысл оценивать значимость уравнения регрессии с коэффициентом детерминации R2 близким к нулю?
Значимость оценивать целесообразно, т.к. даже столь маленькое значение R2 могло получиться не случайно, что нам покажет F тест. Маленькое же значение может говорить о невключении важных факторов. Также, даже при маленьком значении R2 мы можем сделать выводы о виде зависимости между независимым и зависимым показателем, т.е. растет ли Y при росте X или наоборот уменьшается. Это всегда полезно экономисту.
26. В чем состоят ограничения и недостатки практического использования коэффициента детерминации в R2 с точки зрения современных представлений о регрессионном анализе?
Недостатки:
R2 возрастает при добавлении нового регрессора;
R2 изменяется даже при простейшем преобразовании зависимой, поэтому сравнивать по значению R2 можно только регрессии с одинаковыми зависимыми переменными.
Низкое значение R2 не свидетельствует о низком качестве модели, и может объясняться наличием существенных факторов, не включенных в модель
27. Дает ли какую-либо
дополнительную информацию скорректированный коэффициент детерминации ![]() в парном регрессионном анализе?
в парном регрессионном анализе?
Ничего не даёт и не нужен (Черняк).
ТЕМА 2. Интерпретация и использование оценок коэффициентов регрессии в парной линейной регрессии.
28. Как интерпретируется коэффициент при независимой переменной в парной линейной регрессии? (короткая и развернутая форма интерпретации)
y = a + bx. Короткая интерпретация: b – величина, на которую в среднем изменяется значение переменной yi при увеличении независимой переменной x на единицу.
Развернутая: b –величина, на которую изменяется предсказанное по модели значение ŷi при увеличении значения независимой переменной x на одну единицу измерения.
29. Как интерпретируется коэффициент при переменной времени в парной линейной
регрессии? (короткая и развернутая форма интерпретации).
Коэффициент при переменной времени показывает, насколько в среднем изменится зависимая переменная при изменении времени на 1 период.
30. Как интерпретируется коэффициент при индексной переменной (например, при
индексе цен) в парной линейной регрессии? (короткая и развернутая форма
интерпретации)
Коэффициент выражает предельный прирост зависимой переменной при изменении переменной, при условии постоянства других переменных.
Увеличение индексной переменной на 1 процентный пункт приводит к изменению зависимой переменной на β единиц, при условии постоянства других переменных.
31. Как интерпретируется коэффициент при относительной индексной переменной (например, при индексе относительных цен) в парной линейной регрессии? (короткая и развернутая форма интерпретации)
Чем выше значение Индекса Цен, тем больше расходы на соответствующие товары.
Если относительная индексная переменная изменяется на 1 процентный пункт, то это приводит к изменению (в том же направлении) зависимой переменной на β единиц измерения зависимой переменной.
32. В чем смысл и каков способ расчета индекса относительных цен, используемого в эконометрических моделях?
Расчет индекса относительных цен позволяет избавиться от инфляции
Индекс относительных цен = индекс цен/ цена корзины потребительских товаров (индекс цен корзины).
33. Как интерпретируется константа в уравнении линейной регрессии с факторной независимой переменной?
Const дает прогнозируемое значение у (в единицах), если х=0.
Однако всегда важно учитывать смысловую интерпретацию.
34. Как интерпретируется константа в уравнении линейной регрессии с независимой переменной времени?
Константа имеет простое толкование, прогнозируемое значение у будет равно значению этой константы.
Если в качестве независимой переменной - время, то константа - это значение уравнение в предшествующий первому момент времени.
35. Каковы условия интерпретируемости константы в уравнении линейной регрессии?
Константу можно интерпретировать, когда она значима и когда это имеет экономический смысл. Второе условие выполняется для регрессий временного ряда (показывает значение зависимой переменной в базовый период).
Формально говоря, она показывает прогнозируемый уровень, когда х = 0. Иногда это имеет ясный смысл, иногда нет. Если х = 0 находится достаточно далеко от выборочных значений х, то буквальная интерпретация может привести к неверным результатам; даже если линия регрессии довольно точно описывает значения наблюдаемой выборки, нет гарантии, что так же будет при экстраполяции влево или вправо.
Пример:
Представим простой способ интерпретации коэффициентов линейного уравнения регрессии у = a + bх, постоянная а дает прогнозируемое значение у (в единицах), если х = 0. Это может иметь или не иметь ясного смысла в зависимости от конкретной ситуации (стр. 65).
36. Как можно использовать полученные значимые оценки коэффициентов регрессии в экономическом анализе?
Можно предположить, что данный коэффициент показывает предельное изменение зависимого параметра при изменении объясняющей переменной.
37. Как модель регрессии по времени может быть использована для предсказания
значений зависимой переменной?
В модель регрессии по времени включена переменная времени и подставив нужное значение (номер периода, для которого выполняется прогноз) мы получаем прогнозное значение зависимой переменной для данного периода.
38. Каковы условия и ограничения для использования модели регрессии по времени для прогнозирования?
Должны выполняться условия Гаусса-Маркова.
I. Регрессионная модель линейна по параметрам (коэффициентам), корректно специфицирована, и содержит аддитивный случайный член.
II. Случайный член имеет нулевое среднее.
III. Объясняющая переменная не коррелирована со случайным членом.
IV. Наблюдаемые значения случайного члена не коррелированы друг с другом.
V. Случайный член имеет постоянную дисперсию
VI. Случайный член распределен нормально (необязательное, но часто используемое условие).
· Наблюдение должно включать Т+m наблюдений, из которых T – используется для построения регрессии (желательно высокое Т для точности), а последние m применяются для анализа точности предсказания. После проведения проверки можно построить прогноз на ближайшие несколько периодов, в среднем не далее 5% от длины промежутка выборки – чаще еще меньше.
39. Как можно использовать модель регрессии по факторной независимой переменной для прогнозирования?
С помощью регрессии по факторной независимой переменной можно прогнозировать поведение зависимой переменной в зависимости от изменения объясняющей переменной. Если в уравнение регрессии (с оцененными параметрами) подставить какое-то значение объясняющей переменной, то мы получим прогноз реакции зависимой переменной на изменение значения объясняющей переменной.
40. Какие проблемы и трудности возникают при использовании модели регрессии по
факторной независимой переменной для прогнозирования?
Эконометрические модели строятся из-за 2 причин. Во-первых, это прогнозирование; при высоком показателе R2 модель может дать очень хороший прогноз зависимой переменной на будущее. Во-вторых, для объяснения определенных зависимостей; в такой ситуации R2 может быть низким, но зато знак коэффициента при независимой переменной будет определен однозначно, что даст исследователю информацию о виде связи между показателями. Если модель строилась по первой причине и не имеет высокого R-квадрата, использовать ее для прогнозирования бесполезно, так как результат будет далеким от совершенства.
ТЕМА 3. Предпосылки регрессионного анализа. Условия Гаусса-Маркова
41. В чем состоят условия Гаусса-Маркова?
1. Модель линейна по параметрам (коэффициентам), правильно специфицирована, содержит аддитивный случайный член.
2. Объясняющая переменная не коррелированна со случайным членом
3. Математическое ожидание случайного члена равно нулю (E(ui)=0 для всех i)
4. Случайный член гомоскедастичен (то есть его значение в каждом наблюдении получено из распределения с постоянной теоретической дисперсией: σ2ui =σ2u для всех i)
5. Значения случайного члена имеют взаимно независимые распределения (ui распределен независимо от uj для всех j≠i).
6. Случайный член имеет нормальное распределение (необязательное, но часто используемое условие).
42. Какой вывод относительно оцениваемого уравнения регрессии можно сделать из
выполнимости условий Гаусса-Маркова?
МНК-оценка в данном случае является лучшей оценкой в классе линейных.
43. Что произойдет, если по крайней мере одно из условий Гаусса-Маркова не выполняется?
Если не выполняется 1 и 4 условие, то появляется систематическое смещение; если не выполняется 2 и 3 – оценки становятся неэффективными. В обоих случаях модель некорректна.
44. Можно ли проверить выполнение условий Гаусса-Маркова? Если да, то каким образом?
Посмотреть на показатели качества коэффициентов регрессии, а также посмотреть на показатели качества уравнения в целом. Нет интерпретации.
45. На основании чего можно судить о вероятном выполнении или невыполнении условий Гаусса-Маркова?
На основании диаграммы рассеяния, графика остатков. Важно, что случайный член (о котором теорема Гаусса-Маркова) и остатки различны, но их поведение похоже, однако случайный член не наблюдаем, зато остатки легко наблюдаемы. Поэтому мы используем остатки, чтобы судить о свойствах случайного члена.
46. Что означает, что модель линейна по параметрам?
Означает, что модель представляет собой взвешенную сумму параметров, а переменные выступают как веса, иными словами, параметры представлены непосредственно, а не как функции (например, log)
47. Можно ли оценивать методом наименьших квадратов уравнение регрессии без константы?
Нет.
48. В чем состоит роль константы уравнения регрессии?
Роль константы состоит в отражении любой систематической, но постоянной составляющей в зависимой переменной, которую не учитывают объясняющие переменные, включенные в уравнение регрессии, однако, которая оказывает влияние на исследуемую зависимую переменную. Константа интерпретируется в случае соответствия ее значения здравому смыслу или теоретическим предпосылкам.
49. К чему приводит исключение константы из линейного уравнения регрессии?
Исключение постоянного члена приводит к нарушению одного из условия Гаусса-Маркова (о равенстве нулю мат. ожидания случайного члена)
1. Оценки коэффициентов при переменных искажаются и смещаются
2. t-статистики становятся некорректными
Выводы:
1. За редкими и обоснованными исключениями не следует исключать постоянный член уравнения
2. Не следует полагаться на оценку самого свободного члена
50. В каких случаях исключение константы из уравнения регрессии оправдано?
В том случае если константа незначима в уравнении регрессии.
Исключение постоянного члена всегда должно быть обосновано содержательно экономически
Пример: Анализ затрат
Если постоянные затраты малы, то можно исключить свободный член, получив лишнюю степень свободы
Необоснованное исключение свободного члена приводит к серьезным ошибкам!
51. Что значит, что случайный член регрессии является аддитивным?
Это значит, что случайный член прибавляется к другим составляющим частям регрессии.
52. Зачем используется дополнительное условие нормальности распределения случайного члена?
Если случайный член и нормально распределен, то так же будут распределены и коэффициенты регрессии. Это условие необходимо для проводения проверки гипотез и определять доверительные интервалы для a и b, используя результаты построения регрессии.
53. Можно ли использовать уравнение регрессии, если условие нормальности распределения случайного члена не выполняется?
Если условие нормальности распределения случайного члена не выполняется, то неверно предполагать, что оценки коэффициентов регрессии имеют совместное нормальное распределение, однако при некоторых условиях регулярности на поведение объясняющих переменных в случае роста числа наблюдений оценки коэффициентов регрессии имеют асимптотически нормальное распределение. Следовательно, уравнение регрессии использовать можно (по Магнусу).
54. Какие изменения нужно внести в анализ регрессии, если известно, что предположение о нормальности распределения случайного члена регрессии не является справедливым?
Отказаться от использования тестов. Сами оценки регрессии остаются лучшими.
ТЕМА 4. Точность оценки коэффициентов регрессии. Значимость.
55. На основании каких показателей можно судить о качестве коэффициентов регрессионной модели?
- стандартные ошибки – (оценка среднего квадратичного отклонения коэффициента регрессии от его истинного значения)
- значения t-статистики (соизмеряет значение коэффициента с его стандартной ошибкой)
- вспомогательные показатели (p-value, 2-tail sig)
56. Какие из показателей качества регрессии обладают свойством сравнимости для различных моделей? При каких условиях можно сравнивать качество различных регрессионных моделей?
Стандартные ошибки и значения t-статистики.
Кроме этого сравнимы показатели SEE (стандартная ошибка регрессии) в однотипных моделях с разным числом наблюдений (и переменных).
57. В чем состоит смысл понятия «стандартная ошибка коэффициента регрессии»?
Стандартная ошибка является оценкой среднего квадратичного отклонения коэффициента регрессии от его истинного значения. Позволяет получить некоторое представление о форме функции плотности вероятности, однако не несёт информации о том, находится ли полученная оценка в середине распределения (т.е. является точной) или в его «хвосте» (т.е. является относительно неточной).
58. Какова формула для расчета стандартной ошибки коэффициента регрессии?
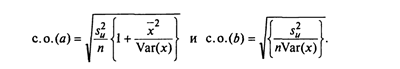 где
где
![]()
см. слайд 9,лекция 4
59. Как связаны между собой оценка дисперсии случайного члена и стандартная ошибка коэффициента регрессии?
Смотреть пункт выше: s![]() -оценка дисперсии
случайного члена, с.o. –стандартная ошибка коэффициентов a и b
регрессии (в новых лекциях SE (a)
и SE (b)).
-оценка дисперсии
случайного члена, с.o. –стандартная ошибка коэффициентов a и b
регрессии (в новых лекциях SE (a)
и SE (b)).
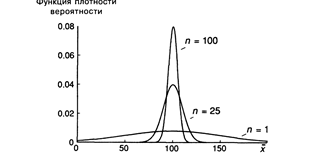
60. Как влияет размер выборки на точность и надежность оценивания в регрессионном анализе.
Чем больше размер выборки, тем уже и выше будет график функции плотности вероятности для х. Если п становится действительно большим, то график функции плотности вероятности будет неотличим от вертикальной прямой, соответствующей х = m. Для такой выборки случайная составляющая х становится действительно очень малой, и поэтому х обязательно будет очень близкой к m.
61. Как использовать точную математическую формулу для оценки влияния размера выборки на точность и надежность коэффициента регрессии?

62. Какое распределение имеет оценка коэффициента линейной регрессии?
Если выполняется предпосылка о нормальном распределении случайного члена, то оценка коэффициента линейной регрессии по методу наименьших квадратов имеет нормальное распределение.
63. В чем состоит смысл вычисления числа степеней свободы для анализа точного распределения оценки коэффициента регрессии?
Чтобы вычислить t-статистику и выявить максимальное число параметров, которые могут быть определены на основе имеющихся данных (из семинара 4).
64. Как рассчитывается число степеней свободы при проверке значимости коэффициента регрессии?
Оценивание каждого параметра в уравнении регрессии поглощает одну степень свободы в выборке. Отсюда число степеней свободы равняется количеству наблюдений в выборке минус количество оцениваемых параметров. Параметрами являются постоянный член (при условии, что он введен в модель регрессии) и коэффициенты при независимых переменных. В случае парной регрессии оцениваются только 2 параметра, поэтому число степеней свободы составляет п — 2.
65. Каким образом выбирается уровень значимости для проверки гипотез о коэффициенте регрессии?
В большинстве работ по экономике за критический уровень берется 5 или 1%. Если нулевая гипотеза отвергается при 1%-ном уровне значимости, то она автоматически отвергается и при 5%-ном уровне значимости. (Причем, если нулевую гипотезу можно отвергнуть при 5%-ном уровне значимости, то не нужно на этом останавливаться. Следует также выполнить тест при уровне значимости 1%. Если нулевая гипотеза может быть отвергнута и при этом уровне значимости, то это и есть нужный ответ.)
В случае же, когда нулевая гипотеза отвергается на 5%-ном, но не на 1%-ном уровне значимости, необходимо представить оба результата.
Если нулевая гипотеза не отвергается при 5%-ном уровне значимости, то это означает, что она автоматически не отвергается и при 1%-ном уровне.
66. Что подразумевается под утверждением, что оценка коэффициента регрессии является значимой?
Коэффициенты регрессии адекватны для нашей модели.
67. Какие способы существуют для определения значимости коэффициента регрессии? (подсказка: их не менее трех)
· критические значения t-статистик Стьюдента для каждого коэффициента регрессии (t-Statistic),
· p-значения (фактические вероятности принятия нулевой гипотезы) для каждого коэффициента регрессии (Prob).
Способов только два (Черняк сказал, что когда он писал вопрос, он «видимо, бредил»)!
68. Каковы практические следствия значимости коэффициента регрессии для прикладного регрессионного анализа?
Модель может быть применима в анализе.
Проверка значимости коэффициентов линейной регрессии заключается в проверке гипотезы значимости или незначимости отличия оценок некоторых регрессионных коэффициентов от нуля. Если в результате проверки оказывается, что отличие оценок каких-то регрессионных коэффициентов от нуля не влияет на качество модели, то соответствующие независимые переменные можно исключить из регрессионной модели.
69. Каковы практические следствия незначимости коэффициента регрессии для прикладного регрессионного анализа?
Возможно, переменная при этом коэффициенте действительно лишняя. Но только по критерию значимости убирать её из модели мы не можем. Главная проблема в том, чтобы понять: влияет переменная с незначимым коэффициентом на зависимую переменную, или её влияние никак не проявляется. Поэтому, если, исходя из теории или логики, переменная в модели необходима, то можно попробовать преобразовать модель или ввести новые переменные.
70. Какие практические выводы можно сделать из значимости свободного члена уравнения регрессии?
Как известно, свободный член выборочного уравнения регрессии дает оценку ожидаемого значения фактора У, при том, что фактор Х равен 0. Такая интерпретация корректна, если в выборке, по которой оценивается модель есть значения Х, близкие к нулю. В противном случае случайному члену не следует придавать содержательного толкования.
71. Какие практические выводы можно сделать из незначимости свободного члена уравнения регрессии?
Т.к. константа незначима, то ее значение можно принять равной нулю, т.е. предположить, что связь между переменными пропорциональная. В этом случае уравнение будет оцениваться маленько другими способами, но опять же с помощью МНК.
72. Коэффициент b2 в оцениваемой регрессии ![]() оказался положительным, но незначимым.
Следует ли отсюда, что коэффициент β2 в гипотетической (теоретической)
регрессии
оказался положительным, но незначимым.
Следует ли отсюда, что коэффициент β2 в гипотетической (теоретической)
регрессии ![]() также положителен? Почему?
также положителен? Почему?
Нет, не следует, так как мы получаем только оценки, а они могут быть неточными.
73. Коэффициент b2 в оцениваемой регрессии ![]() оказался положительным, и значимым. Следует
ли отсюда, что коэффициент β2 в гипотетической
(теоретической) регрессии
оказался положительным, и значимым. Следует
ли отсюда, что коэффициент β2 в гипотетической
(теоретической) регрессии ![]() также положителен?
Почему?
также положителен?
Почему?
Необязательно.
Это будет так, если в доверительный интервал (который строится относительно фактических данных) войдет только отрезок из положительных чисел.
Если же одна из границ захватит отрицательные числа, то необязательно коэффициент в теоретической регрессии также будет положительным.
74. Почему по величине коэффициента регрессии нельзя судить о силе связи двух переменных?
Нельзя судить, потому что коэффициент регрессии дает оценку отношения изменения фактора У к вызвавшему это изменение значению фактора Х, а никак не показывает силу связи между двумя переменными. Коэффициент регрессии показывает на какую величину в среднем изменяется результативный признак у при изменении факторного признака Х на единицу.
75. Почему положительный результат проверки на значимость не позволяет обосновать теоретическую модель регрессии?
Потому что это только один из аргументов. Если коэффициент значим, то это хорошая новость, но это не дает никаких гарантий. Может возникнуть много других проблем, например, коэффициент может оказаться смещен из-за пропуска существенных переменных в модели.
76. Почему t-статистики нельзя использовать для анализа данных по всей изучаемой совокупности?
По t-статистике по данным определенной выборки нельзя судить о данных по всей совокупности, она используется только для данной конкретной выборки. Только в случае, если эту выборку можно считать репрезентативной для всей совокупности, тогда t-статистику можно использовать для анализа.
77. Почему могут существовать несколько «одинаково хороших» парных регрессий
влияния разных факторов на одну и ту же зависимую переменную?
Потому что на каждую переменную в равной степени могут влиять различные факторы, все из которых учесть невозможно. В связи с этим возникает несколько «хороших» парных регрессий с «хорошими» факторами.
ТЕМА 5. Проверка гипотез о коэффициентах регрессии
77-1. Как проверить гипотезу о нулевом значении теоретического коэффициента регрессии?
Для проверки нулевой гипотезы
H0 о равенстве нулю некоторого коэффициента регрессионного уравнения (H0:β2=0,
H0: β2≠0) необходимо
сравнить фактическое значение статистики, найденное по формуле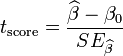 с критическим
значением t-статистики Стьюдента для выбранного уровня значимости, то есть со
значением двусторонней (1-α) квантили t-статистики Стьюдента с n-k
степенями свободы. Величина α характеризует допустимый уровень вероятности
ошибиться, отвергнув нулевую гипотезу, когда она верна.
с критическим
значением t-статистики Стьюдента для выбранного уровня значимости, то есть со
значением двусторонней (1-α) квантили t-статистики Стьюдента с n-k
степенями свободы. Величина α характеризует допустимый уровень вероятности
ошибиться, отвергнув нулевую гипотезу, когда она верна.
Если фактическое значение t-статистики Стьюдента больше критического значения статистики, то нулевая гипотеза отвергается для данного уровня значимости α, иначе нулевая гипотеза не может быть отвергнута для данного уровня значимости α. В случае отвержения нулевой гипотезы для уровня значимости говорят, что коэффициент β регрессионного уравнения значим на уровне значимости α (или, говорят, что оценка коэффициента β значимо отличается от нуля), и соответствующий ему регрессор объясняет вариацию зависимой переменной. В противном случае говорят, что коэффициент незначим на уровне значимости α.
Второй способ проверки гипотезы – сравнить p-значение (фактическую вероятность принятия нулевой гипотезы данного коэффициента регрессии) с выбранным уровнем значимости. Если выполняется условие p< α , то нулевая гипотеза отвергается на уровне значимости α, иначе нулевая гипотеза не может быть отвергнута для данного уровня значимости α .
78. Как проверить гипотезу о нестандартном (ненулевом) значении теоретического коэффициента регрессии?
Для этого предполагаем, что Н0: β2=0. H0: β2≠0. Критической статистикой для этой гипотезы выступает t-статистика. T стат. = T критическое = t критич (n-2, ɑ)
Если |t стат|>|t критич|, то гипотеза H0 отвергается, если меньше, то подтверждается
79. Что такое p-значение (p-value, обозначаемое в программе EViews как Prob.) для
статистического критерия?
Метод p-value («метод значения вероятность») p-value = Prob – вероятность того, что случайно будет получен результат лучше, чем у нас (тот, что рассчитан). Если p-value маленький, то это хорошо, а если большой, то плохо.
80. В чем заключается техника работы с p-значением при проверке гипотез?
Смотрим значение prob. в таблице с результатами регрессии и сравниваем с 0,01 и 0,05.
Если prob < 0,01, то коэффициент (уравнение) значим на 1% уровне.
Если 0,01 < prob < 0,05, то коэффициент (уравнение) значим только на 5% уровне.
Иначе коэффициент (уравнение) не значим.
81. Как рассчитать p-значение в случае, если невозможно получить доступ к эконометрической программе, или в ней не предусмотрен его расчет?
Открываем
таблицу t-распределения, смотрим ряд для нашего числа
степеней свободы. Если в нем есть значение t-статистики
для рассматриваемого параметра, то уровень значимости (верх таблицы) будет как
раз искомым значением p. Если значение t-статистики располагается между двумя табличными, то на основе
значений для двух табличных можно приближенно рассчитать искомое по формуле ![]() , где t – значение t-статистики, t1 – первое из табличных значений, t2
– второе (большее, правее первого в ряду), а p1 и p2 – значения p соответственно для
первого и второго табличных значений t-статистики.
, где t – значение t-статистики, t1 – первое из табличных значений, t2
– второе (большее, правее первого в ряду), а p1 и p2 – значения p соответственно для
первого и второго табличных значений t-статистики.
82. Что такое ошибки первого и второго рода в проверке гипотез о коэффициентах регрессии?
Ошибка I рода состоит в том, что мы отвергаем Н0, когда на самом деле она истина.
Ошибка II рода имеет место в случае, если мы принимаем Н0, когда она ложна.
83. Какова связь ошибок первого и второго рода при проверке гипотез о коэффициентах регрессии?
При уменьшении вероятности ошибки 1ого рода увеличивается вероятность ошибки 2ого рода.
84. Что такое мощность критерия?
Мощность критерия (теста)- это вероятность допустить ошибку II рода (β), то есть принять ложную гипотезу. Вычисляется по формуле (1 − β). Таким образом, чем выше мощность, тем меньше вероятность совершить ошибку второго рода. Используя односторонний критерий вместо двустороннего, можно получить большую мощность при любом уровне значимости. Нужно, однако, помнить, что выигрыш в мощности будет получен только в условиях, когда использование одностороннего критерия оправдано.
ТЕМА 6. Доверительные интервалы для коэффициентов регрессии.
85. Как использовать метод доверительных интервалов для установления значимости коэффициента регрессии?
Если полученный коэффициент регрессии попадает в построенный доверительный интервал, то соответственно он считается значимым.
86. Как использовать метод доверительных интервалов для проверки гипотезы о
конкретном значении коэффициента регрессии (отличном от нуля)?
Нужно проверить нулевую
гипотезу (H0) о каком-то конкретном значении
коэффициента ![]() . Его возможных значений, близких к
значению эксперимента, может быть несколько. Но, начиная с какого-то момента
они будут отличаться настолько, что мы отклоним нулевую. Смысл доверительного
интервала – найти условие (интервал), в котором наше гипотетическое
. Его возможных значений, близких к
значению эксперимента, может быть несколько. Но, начиная с какого-то момента
они будут отличаться настолько, что мы отклоним нулевую. Смысл доверительного
интервала – найти условие (интервал), в котором наше гипотетическое ![]() совместимо со значением коэффициента
регрессии b
совместимо со значением коэффициента
регрессии b![]() (т.е. значение
(т.е. значение ![]() не
опровергается оценкой b
не
опровергается оценкой b![]() ).
).
Для построения интервала найдём табличные значения:
·
выберем уровень значимости (![]() ) 1%
или 5%.
) 1%
или 5%.
·
рассчитаем количество степеней свободы (n-2),
вычисляем t![]() критическое
при двустороннем интервале по таблице распределения Стьюдента.
критическое
при двустороннем интервале по таблице распределения Стьюдента.
После этого следует вычислить границы доверительного интервала следующим образом:
![]()
87. Как выбирается уровень доверительной вероятности при использовании метода
доверительных интервалов при проверке значимости коэффициента регрессии?
Зависит от того, на каком уровне значимости (1% или 5%) отвергается нулевая гипотеза Н0. Если на 1% уровне, то строим 99% доверительный интервал, если на 5%, то 95% доверительный интервал. 99% интервал будет шире, чем 95%, так как t критич будет больше для 1% ого уровня значимости.
88. В чем сходство и различие методов проверки гипотез и доверительных интервалов?
Для двусторонних тестов они эквивалентны. Односторонних интервалов просто не бывает, а односторонние гипотезы вполне работают (ответ Черняка).
ТЕМА 7. Двусторонние и односторонние тесты.
89. В чем различие между двусторонним и односторонним критериями?
При двустороннем тесте мы проверяем гипотезу H0:β=β0(в частности, β=0), используя альтернативную гипотезу H1:β≠β0.
При одностороннем тесте альтернативная гипотеза меняется на H1:β>β0 и H1:β<β0 в зависимости от того, какое влияние оказывает x на y (положительное или отрицательное соответственно). При этом у нас должны быть веские причины считать, что это влияние положительно/отрицательно.
90. В каких случаях можно использовать односторонние критерии при проверке гипотез о коэффициенте регрессии, и что это дает?
Риск одностороннего критерия в том, что он может назвать значимой переменную, которая не является значимой на самом деле. Односторонний критерий – это шанс назвать вашу переменную значимой, когда двусторонний критерий не срабатывает.
Единственное условие, при котором вы можете его применять, это если гипотеза о значимости переменной и ее важности в уравнении регрессии была построена до того, как EViews разочаровал Вас. Это вопрос этики, поскольку тесты созданы для проверки гипотезы, придумывание гипотез по результатам теста – порочный круг.
Вы протестировали регрессию, получили что важный с вашей точки зрения коэффициент не значим на двустороннем уровне, но значим по одностороннему критерию. Тогда, логически и экономически обосновывая свою позицию, что «все равно, я считаю эту переменную важной», вы присуждаете ей значимость на одностороннем критерии.
91. Каково соотношение между двусторонним и односторонним тестами? Пусть двусторонний тест позволил отвергнуть нулевую гипотезу. Что можно сказать об одностороннем тесте?
Когда имеются основания для применения одностороннего теста, его следует предпочесть двустороннему. Односторонний критерий имеет меньшую вероятность ошибки второго рода, чем соответствующий двусторонний. Поэтому, когда нет необходимости применять двусторонний критерий, применяют односторонний.
Односторонний тест – тест на проверку гипотезы, в котором область принятия гипотезы имеет только одно критическое значение, в отличие от двустороннего теста, в котором область принятия гипотезы имеет два критических значения – меньшее и большее.
Если двусторонний тест отвергнул нулевую гипотезу, то есть вероятность принятия ее односторонним.
92. Каково соотношение между двусторонним и односторонним тестами? Пусть двусторонний тест не позволил отвергнуть нулевую гипотезу. Что можно сказать об одностороннем тесте?
Если нулевая гипотеза не опровергается при двустороннем тесте, то есть шанс, что она будет отвернута при одностороннем, при условии, что нам известно направление влияния фактора.
93. Каково соотношение между двусторонним и односторонним тестами? Пусть односторонний тест позволил отвергнуть нулевую гипотезу. Что можно сказать о двустороннем тесте?
В случае, когда мы достаточно точно можем предположить направление влияния переменной, можем использовать односторонний тест. В это случае нулевая гипотеза всё та же H(0) : B=0, А альтернативная гипотеза меняется по сравнению с двусторонним тестом. Мы можем принять гипотезу
H(1): B>0 или H(1): B<0 , в зависимости от предполагаемого направления влияния. Использование одностороннего критерия облегчает отклонение нулевой гипотезы и установление зависимости.
94. Каково соотношение между двусторонним и односторонним тестами? Пусть односторонний тест не позволил отвергнуть нулевую гипотезу. Что можно сказать об двустороннем тесте?
Двусторонние тесты более строгие в отличие от односторонних. Коэффициент может быть незначим при двустороннем тесте и значим при одностороннем, поэтому использование односторонних тестов может оказаться полезным, так как хочется иметь значимые коэффициенты.
Если односторонний тест не позволил отвергнуть нулевую гипотезу, то есть значимость коэффициента обосновать не удалось, то более строгий двусторонний тест также не отвергнет нулевую гипотезу, и коэффициент является незначимым.
ТЕМА 8. F-тест для оценки уровня качества уравнения парной регрессии.
95. Для чего используется F-критерий при оценке качества уравнения регрессии?
F-тест проверяет совместную объясняющую способность всех объясняющих переменных.
Нулевая гипотеза заключается в том, что модель не обладает никакой объясняющей способностью. Если расчетная F-статистика больше табличной, то нулевая гипотеза отвергается.
96. Как рассчитать значение F-критерия, исходя из знания сумм квадратов остатков?
![]() , где ESS – сумма квадратов остатков, RSS – объясненная сумма квадратов, n – число наблюдений, k – число параметров. Если известно TSS
(общая сумма квадратов), RSS рассчитывается
с помощью формулы
, где ESS – сумма квадратов остатков, RSS – объясненная сумма квадратов, n – число наблюдений, k – число параметров. Если известно TSS
(общая сумма квадратов), RSS рассчитывается
с помощью формулы ![]() .
.
97. Как рассчитать значение F-критерия, исходя из знания коэффициента детерминации R2?
![]()
(Если F>Fкр, то отклоняет нулевая гипотеза *о незначимости*)
98. Как рассчитывается число степеней свободы для F-критерия в парной регрессии?
n-2, где n – количество наблюдений; 2 – количество оцениваемых параметров в парной регрессии.
99. Каков вид F-распределения? Почему обычно используются только односторонние F-критерии?
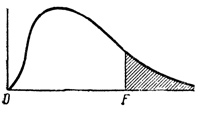
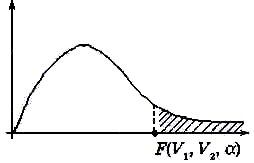
Гипотеза Ho отвергается, если попадаем в заштрихованную область. Критерий дносторонний.
Односторонний критерий имеет более высокую мощность, чем двухсторонний критерий — при той же вероятности ошибочного отклонения нулевой гипотезы. Это говорит о предпочтительности одностороннего критерия по сравнению с двухсторонним.
100. Каков содержательный смысл отношения Фишера в определении F-критерия?
С помощью отношения Фишера мы определяем критический уровень для R2 при любом уровне значимости.
101. Каковы общие принципы выбора уровня значимости при использовании F-критерия для оценки качества уравнения в целом?
Критический уровень в 1% выше критического уровня для проверки при 5% уровне значимости. При выборе 1% уровня значимости вероятность ошибки 1 рода = 1%
102. Как использовать таблицы F-распределения при проведении F-теста?
F(а, k-1, n-k-1): а – уровень значимости. K – число объясняющих переменных с константой, n-k-1= число наблюдений – число объясняющих переменных без константы. Смотрим число, находящееся на пересечении столбца (k-1) и строки (n-k-1). F-распределение всегда одностороннее.
103. Какова связь между F-критерием и t-критерием для коэффициента регрессии? Какова связь между соответствующими критическими значениями?
Fстат.=tстат.2 Fкр.(α,n-z)=t2кр.(α, n-z, двустор.)
104. Что означает эквивалентность F-критерия и t-критерия для парной регрессии?
В парном регрессионном анализе F-критерий и t- критерий имеют одинаковые нулевые гипотезы, и эти критерии эквивалентны друг другу. Тот факт, что они эквивалентны, означает, что нет смысла выполнять оба этих теста.
105. Как проверить гипотезу о значимости коэффициента корреляции?
Коэффициент корреляции указывает на наличие (или отсутствие) линейной связи между зависимой и независимой переменной. Гипотеза о значимости коэффициента корреляции проверяется при помощи t-статистики.
Для
проверки гипотезы об отсутствии линейной связи используется тот факт, что величина
![]() имеет распределение Стьюдента с n – 2 степенями свободы.
имеет распределение Стьюдента с n – 2 степенями свободы.
t-статистики для коэффициента корреляции и для коэффициента регрессии совпадают. Проверка значимости коэффициента регрессии эквивалентна проверке наличия линейной связи.
106. Как, исходя из коэффициента детерминации, проверить гипотезу о значимости линейной связи между переменными?
Коэффициент детерминации R-squared дает предварительную оценку качества модели (от 0 до 1). Он показывает долю объясненной дисперсии зависимой переменной, эквивалентен принципу наименьших квадратов. В практике линейная связь считается значимой, если R-squared (0,6-1). Однако нужно помнить, что слишком высокий R-squared может быть тревожным сигналом (несовершенство связи, например, наличие мультиколлинеарности).. Если R-squared недостаточно высок (0-0,5), значит нужно совершенствовать и дорабатывать модель.
Коэффициент детерминации не позволяет дать окончательного заключения без учета других факторов. Он подвержен влиянию посторонних факторов и может привести к ошибочному выводу. Если отсутствуют таблицы для критических значений, на его основе нужно рассчитывать другие показатели.
107. Для чего используется показатель стандартной ошибки уравнения регрессии?
Стандартная ошибка – оценка среднего квадратического отклонения значения коэффициента от его истинного значения.
Стандартная ошибка указывается для расчета значения t-статистики вручную. Сопоставляя их следующим образом t=b/s.e.(b), мы получаем информацию о значимости регрессии: чем больше t, тем больше шансов, что он окажется значимым.
Дополнительно:
Стандартная ошибка является оценкой среднего квадратичного отклонения коэффициента регрессии от его истинного значения
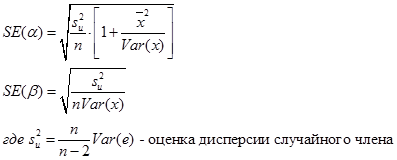
Практическая формула расчета стандартной ошибки коэффициента парной регрессии:
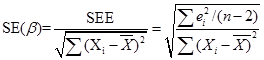
Сравнивая значение коэффициента с его стандартной ошибкой, можно судить о значимости коэффициента.
Для стандартных ошибок нет таблиц критических уровней – для точного суждения используется t-статистика. Стандартная ошибка необходима для расчета t-критерия.
ТЕМА 9. Оценивание нелинейных моделей парной регрессии.
108. В каких случаях можно использовать метод наименьших квадратов для оценивания нелинейных моделей?
МНК можно применять к нелинейным регрессионным моделям только в том случае, если они являются нелинейными по независимым переменным или нелинейными по параметрам, но внутренне они линейны, т. е. возможна линеаризация этих моделей (замены нелинейной системы линейной) это возможно с помощью логарифмирования или обратного преобразования (инверсия)
Случайный член - мультипликативный удовлетворяет условиям Гаусса-Маркова, для функции y = αxb.
109. Какие преобразования следует выполнить для оценивания нелинейных моделей
методом наименьших квадратов?
1. Если правая часть уравнения нелинейна по переменным (линейность по переменным означает, что правая часть состоит из взвешенной суммы переменных, а параметры являются весами), то эту нелинейность можно обойти путем замены соответствующих нелинейных переменных. Например:
![]()
заменим: ![]()
тогда: ![]()
Данное преобразование является лишь косметическим и позволяет избежать лишних обозначений.
2. Если правая часть уравнения нелинейна по параметрам (линейность по параметрам означает, что правая часть состоит из взвешенной суммы параметров, а переменные являются весами), то преобразование в линейную функцию производится путём логарифмического преобразования, использую основные свойства логарифмов (в расчётах используются натуральные логарифмы):
a.
если ![]() ,то
,то ![]() ;
;
b.
если ![]() ,то
,то ![]() ;
;
c.
если ![]() ,то
,то ![]() ;
;
d.
если ![]() ,то
,то ![]() .
.
Например:
Если ![]() , то
, то ![]() .
.
Если ![]() , то
, то ![]() – полулогарифмическая модель
(логарифмически-линейная).
– полулогарифмическая модель
(логарифмически-линейная).
3. Модели типа: ![]() – не могут быть преобразованы в
уравнения линейного вида, поэтому в данном случае применение обычной процедуры
оценивания модели регрессии невозможно, но для получения оценок параметров
по-прежнему применяется принцип минимизации суммы квадратов отклонений.
– не могут быть преобразованы в
уравнения линейного вида, поэтому в данном случае применение обычной процедуры
оценивания модели регрессии невозможно, но для получения оценок параметров
по-прежнему применяется принцип минимизации суммы квадратов отклонений.
110. Какие конкретные типы нелинейных моделей пригодны для оценивания
нелинейных моделей методом наименьших квадратов?
y=α+b/x и y=αxb, т.е. модели нелинейные по переменным.
Все логарифмические зависимости могут быть оценены МНК
Функция Кобба-Дугласа может быть приведена к логарифмической зависимости:
![]()
МНК применим также для полиномиальных форм:
![]()
111. В каких случаях при оценивании нелинейных моделей метод наименьших квадратов оказывается неприменимым?
y=αxb+u. Аддитивный случайный член не дает нам прологарифмировать функцию данного вида.
112. Что делать, если модель не приводится к виду, допускающую использование
метода наименьших квадратов?
Использовать метод оценивания нелинейной регрессии Бокса-Кокса по следующему алгоритму:
1. Преобразуем зависимую переменную по методу Зарембки
![]()
2. Рассчитываем новые переменные (преобразование Бокса-Кокса) при λ от 1 до 0.
![]()
![]()
3. Рассчитываем регрессии для новых переменных при значениях λ от 1 до 0.
![]()
4. Выбираем минимальное значение суммы квадратов остатков (SSR), выбираем одну из крайних регрессий, к которой ближе точка минимума
ТЕМА 10. Интерпретация и использование нелинейных моделей парной регрессии.
113. Для чего нужны нелинейные эконометрические модели?
Нелинейные соотношения гораздо лучше подходят для описания многих экономических процессов, чем линейные.
Пример:
1. Анализ роста
Теоретический феномен – экономический рост
Анализ предпосылок: прирост пропорционален накопленному потенциалу
Формализация предпосылок:
![]()
Интерпретация и анализ: коэффициент регрессии «бета» - годовой темп роста, возможно сопоставление с реальными данными
2. описание кривых Энгеля, характеризующих соотношение между спросом на определённый товар Y и общей суммой дохода Х (подробное описание в 3-ем издании учебника Доугерти, стр.162-164).
114. Исходя из каких соображений и в каком порядке следует выбирать форму зависимости для эконометрической модели?
Из соображений графического соответствия, расчета эластичности и угла наклона, а также по тем соображениям, какая задача стоит перед нашей моделью и по теоретическим соответствиям о природе тех или иных зависимостей.
Выбираем из:
1. Линейные зависимости – самые простые зависисмости, всегда оставляем ее, если нет логического подтверждения необходимости иной спецификации.
2. Логарифмические зависимости – В зависимости от значений коэффициентов регрессии
Логарифмические зависимости отображают большое разнообразие форм, логарифмические зависимости помогают уменьшить масштаб переменных для их сравнимости.
3. Полулогарифмические зависимости – В зависимости от значений коэффициентов регрессии полулогарифмические зависимости отображают большое разнообразие форм с эффектом насыщения
4. Полиноминальные зависимости - Эти функции хорошо подходят для моделирования эффекта масштаба, анализа максимумов и минимумов
5. Обратные зависимости – Эти функции хорошо подходят для моделирования эффектов полного насыщения и ограниченности
115. Как интерпретируется коэффициент линейной формы регрессионной модели? Как можно обосновать справедливость предложенной интерпретации?
Линейная форма: ![]()
Интерпретация коэффициентов регрессии – предельный эффект независимого фактора.
![]()
Для полученных оценок уравнения регрессии
![]()
![]()
![]()
![]()
![]()
Т.е коэффициент регрессии показывает прирост результирующей переменной при изменении независимого фактора на единицу
116. В каких случаях оправдано использование линейной регрессии?
1. Если в этом есть экономический смысл
2. Если модель получилась формально качественной
Другой ответ:
В случае, когда необходимо рассчитать линейную связь между зависимой и независимой переменной, а затем использовать эту связь при прогнозировании, то есть используется для прогнозирования будущих значений параметра у исходя из имеющихся данных.
117. Как вычислить эластичности в каждой точке в случае использования линейной регрессии, и для чего можно использовать этот показатель?
E=(Δy/Δx)*x/y=bx/y. Для исследования того, является ли функция y=αxb приемлемой.
118. Как интерпретируется коэффициент дважды логарифмической формы регрессионной модели? Как можно обосновать справедливость предложенной интерпретации?
![]() =>
=> ![]() Коэффициент
интерпретируется следующим образом: эластичность Y по Х
постоянна и равна
Коэффициент
интерпретируется следующим образом: эластичность Y по Х
постоянна и равна ![]() .
.
На сколько % изменится y при изменении x на 1 %. dy/y=b*dx/x => b=(dy/dx)*x/y
119. В каких случаях оправдано использование двойной логарифмической формы регрессии?
Используем там, где есть основание. Предполагаем постоянство эластичности. y’=α’xibu’ => lny= lnα+blnxi+u
120. Как рассчитать предельный эффект фактора в каждой точке в дважды логарифмической регрессионной зависимости?
Вычисление коэффициента наклона (скорости роста фактора), (dy/dx)=b*x/y
121. Каких видов существуют полулогарифмические регрессии?
1) линейно-логарифмические (![]() )
)
2) логарифмически-линейные (![]() )
)
122. Как интерпретируется коэффициент линейно-логарифмической формы регрессионной модели? Как можно обосновать справедливость предложенной интерпретации?
y= α+bx+u, dy=bdx/x => b=(dy/dx)*x. при интерпретации делим на b/100. На сколько возрастет y при росте x на 1%
123. В каких случаях оправдано использование линейно-логарифмической формы регрессии?
Там, где эластичность убывает с ростом y.
Линейно-логарифмические модели обычно используются в тех случаях, когда необходимо исследовать влияние процентного изменения независимой переменной на абсолютное изменение зависимой переменной.
124. Как рассчитать и использовать эластичность при использовании линейно-логарифмической формы регрессионной модели?
Пусть
эластичность постоянна: ![]()
![]()
Коэффициент регрессии при переменной log X выражает эластичность зависимой переменной у по переменной X при условии постоянства других переменных.
125. Как интерпретируется коэффициент логарифмически-линейной формы регрессионной модели? Как можно обосновать справедливость предложенной интерпретации?
lny=lnα+blnxi+u. На сколько процентов (x/100) возрастет y при изменении x на единицу. dy/y=bdx => b=dy/dx*y. b*100
126. В каких случаях оправдано использование логарифмически-линейной формы регрессии?
Если зависимость между у и х задана в нелинейной форме, например у=αхb,т.е. когда речь идет о степенных функциях. Эластичность растет с ростом x
127. Как рассчитать и использовать эластичность при использовании логарифмически-линейной формы зависимости?
Аналогичен следующему.
128. Как рассчитать и использовать эластичность при использовании логарифмически-линейной формы зависимости?
Для логарифмически-линейной функции вида
![]()
эластичность рассчитывается по формуле
![]()
Ее можно использовать для отображения величины реакции изменения зависимого параметра от независимого.
129. Как используется логарифмически-линейной формы регрессии по времени? Какова интерпретация коэффициента регрессии?
Имеем показательную функцию вида y=αert. logy=logα+rt. оценивая регрессию между logy и t мы получаем оценку темпа прироста r. Обычно речь идет о процентных темпах прироста. Постоянный множитель α интерпретируется след. образом: «прогнозируется», что в момент t=0 величина y составит α ед. А темп прироста y составит r*100% в год. Удобен для построения моделей экономического роста.
130. Как интерпретируется обратно пропорциональная регрессионная зависимость модели? Как можно обосновать справедливость предложенной интерпретации?
![]()
С ростом X зависимая переменная приближается к некоторому числу (моделирование эффекта насыщения).
131. В каких случаях оправдано использование обратно пропорциональной регрессионной зависимости?
Если с ростом x зависимая переменная приближается к какому-то числу.
132. Как рассчитать и использовать эластичности для обратно пропорциональной регрессионной зависимости?
![]()
При возрастании x на 1%, y снизится на столько процентов (b*(1/xy)). Т.к. эластичность напрямую зависит от переменной x, то можно посчитать значение эластичности для каждого x (или для нужного х), а чаще всего берется среднее х.
ТЕМА 11. Сравнение нелинейных регрессионных моделей.
133. При сравнении каких моделей нужно использовать преобразование Зарембки?
При
выборе между линейной и лог линейной моделью, делается преобразование Зарембки
зависимой переменной, строятся модели для этой преобразованной переменной, а потом
сравниваются суммы квадратов остатков, отношение которых имеет распределение ![]() .
.
134. Что дает использование преобразования Зарембки?
Оценку значимости наблюдаемых различий. Можем выявить, какая из моделей является более качественной.
135. В чем состоит идея метода Зарембки?
Метод Зарембки применяется для выбора из двух форм моделей (несравнимых непосредственно), в одной из которых зависимая переменная входит с логарифмом, а в другой – нет. Данный метод позволяет сравнить линейную и логарифмическую регрессии и оценить значимость наблюдаемых различий. Эти регрессии непосредственно несравнимы, так как логарифмы на много порядков меньше самих чисел. Чтобы сделать их сравнимыми, нужно выполнить специальное преобразование (преобразование Зарембки).
1. Вычисляем среднее геометрическое значений
зависимой переменной и все ее значения делятся на это среднее: 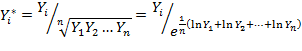
2. Рассчитываются линейная и логарифмическая
регрессии и сравниваются значения их суммы квадратов остатков (SSR): ![]()
![]()
3. Вычисляем χ2-статистику для оценки
значимости различий: ![]()
4. Сравниваем с критическим значением χ2-распределения с одной степенью свободы, различия значимы, если χ2> χ2крит.
В Eviews:
1.Genr logY=log(Y)
2.Genr Ys=Y/exp(@mean(logY))
3.ls Ys c Х
4.Сравним полученные значения SSR.
Лучшей считается модель, в которой значения SSR меньше.
136. При сравнении каких моделей метод Зарембки применять не нужно?
Метод Зарембки применим для выбора из двух форм моделей (несравнимых непосредственно), в одной из которых зависимая переменная входит с логарифмом, а в другой - нет. Метод позволяет сравнить линейную и логарифмическую регрессии и оценить значимость наблюдаемых различий.
Не нужно применять данный метод для уравнений одной функциональной формы, а так же для сравнения между собой иных форм, кроме линейной и логарифмической (двойная-логарифмическая; линейно-логарифмическая; обратная).
137. Как формулируется нулевая гипотеза при проведении теста Бокса-Кока для
сравнения двух моделей?
Суммы квадратов остатков двух сравниваемых моделей равны.
138. Как проводится тест Бокса-Кокса для сравнения качества двух моделей?
Тест Бокса-Кокса состоит в преобразовании масштаба наблюдений переменной Y , для обеспечения возможности сравнения RSS линейной и логарифмических моделей.
1) Вычисляется среднее геометрическое значение Y в выборке. Оно совпадает с экспонентой среднего арифметического log Y, которое легко рассчитать
![]() =
= ![]()
2) Теперь пересчитываются значения Y, они делятся на среднее геометрическое Y
![]()
3)
Оцениваются регрессии как в линейной, так и в логарифмической модели с
использованием ![]() вместо Y и
log
вместо Y и
log ![]() вместо
logy
вместо
logy
Таким образом, теперь можно сравнивать сумму квадратов остатков(RSS).
Чем сумма меньше, тем модель лучше
139. На основании чего проводится выбор модели, если тест Бокса-Кокса указывает на необходимость отвергнуть нулевую гипотезу?
Выбор модели проводится на основании минимального значения суммы квадратов остатков при разных значениях лямбда, и выбирается одна из крайних регрессий, к которой ближе находится эта точка минимума.
140. На основании чего проводится выбор модели, если тест Бокса-Кокса указывает на невозможность отвергнуть нулевую гипотезу?
Если тест Бокса-Кокса указывает на невозможность отвергнуть нулевую гипотезу , то выбор модели производится на основе экономических соображений и сравнении других показателей модели (например, R²).
ТЕМА 12. Интерпретация и использование моделей множественной линейной регрессии.
141. В чем особенность интерпретации коэффициентов регрессии в случае нескольких независимых переменных?
При множественном регрессионном анализе существенен вопрос разграничения эффекта влияния данной независимой переменной на зависимую от воздействия других независимых переменных. Другая проблема заключается в оценке объективной объясняющей способности независимых переменных в противоположность их отдельным предельным эффектам.
142. Какова интерпретация коэффициентов множественной линейной регрессии?
Классическая
линейная регрессия имеет вид ![]()
Интерпретация регрессии: коэффициент регрессии при переменной X1 выражает предельный прирост зависимой переменной при изменении переменной X1 и при условии постоянства других переменных. То есть:
![]()
143. Какова интерпретация коэффициентов множественной логарифмической регрессии (логарифмы при всех переменных)?
Y i = α + β1 logX1i + β2 logX2i + + ui
Коэффициент регрессии при переменной X1 выражает предельный прирост зависимой переменной при изменении переменной X1, при условии постоянства других переменных.
144. Какова интерпретация коэффициентов множественной логарифмической регрессии, включающей время (логарифмы при всех переменных, кроме времени)?
logY i =α+β1logX1i +β2logX2i + β3t +ui
Интерпретация коэффициентов множественной логарифмической регрессии: коэффициент регрессии при переменной logX1 выражает эластичность зависимой переменной по переменной X1 в момент времени t, при условии постоянства других переменных.
145. В чем особенность расчетных формул для коэффициентов множественной линейной регрессии? Какие дополнительные факторы они учитывают?
Значение коэффициента регрессии дополнительно учитывает не только связи изучаемого фактора с зависимой переменной, но и структуру связей между независимыми переменными.
146. Какова структура связей в уравнении множественной регрессии и каким образом ее следует учитывать при анализе уравнения?
В множественной регрессии есть переменные которые непосредственно влияют на зависимую переменную – то есть включены в модель. и те, которые влияют опосредованно, так как напрямую в модель не включены. это стоит учитывать, так как при невключении важной переменной, оставшиеся переменные в модели будут отражать вклад этой переменной, что может привести к смещению оценок коэффициентов и нерепрезентативности индикаторов качества регрессии в целом (t, F статистик).
при невозможности включить важную переменную, нужно включить максимально коррелированную с ней замещающую переменную.
147. Можно ли сравнивать коэффициенты регрессии по их величине и использовать это сравнение для оценка значимости вклада каждой из переменной?
Значение коэффициентов в множественной регрессии показывает предельный вклад каждой переменной в объяснение дисперсии значений зависимой переменной. Однако напрямую сравнивать их нельзя – надо учитывать единицы измерения и различные содержательные вопросы. Так например, в упражнении 1 семинара 6 нельзя напрямую сравнивать коэффициенты регрессии – надо учитывать трудоемкость. Иначе говоря, надо учитывать дополнительные содержательные факторы, и тогда сравнивать можно.
ТЕМА 13. Качество уравнения множественной регрессии.
148. Какими свойствами обладают оценки коэффициентов регрессии, полученные методом наименьших квадратов в случае выполнимости условий теоремы Гаусса-Маркова?
Оценки коэффициентов при использовании МНК и при соблюдении условий теоремы Гаусса-Маркова будут наиболее эффективными, линейными (комбинациями Y) и несмещенными.
149. Каковы последствия для свойств оценок коэффициентов регрессии, полученных
методом наименьших квадратов, в случае невыполнения условий теоремы Гаусса-
Маркова?
Если не выполняется второе условие Мат ожидание остатков ![]() , то оценка коэффициентов для парной
регрессии будет смещена, неэффективна и несостоятельна.
, то оценка коэффициентов для парной
регрессии будет смещена, неэффективна и несостоятельна.
Если не выполняется пятое условие, ![]() ,
то появляется гетероскедастичность и оценка будет несмещенной, но
неэффективной, но может быть состоятельной.
,
то появляется гетероскедастичность и оценка будет несмещенной, но
неэффективной, но может быть состоятельной.
150. Какие факторы дополнительно учитывает формула для расчета стандартной ошибки в случае множественной регрессии, по сравнению с аналогичной формулой для парной регрессии?
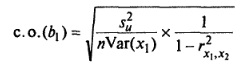
В случае множественной регрессии формула с.о. учитывает еще коэффициент корреляции между независимыми переменными. Если коэффициент корреляции близок к единице, т.е. существует тесная связь между переменными, то с.о. будет большой, что отражает вероятную неточность коэффициентов регрессии.
151. Каковы показатели качества уравнения регрессии в целом?
Показатели качества коэффициентов регрессии:
· Стандартные ошибки коэффициентов
· Значения t-статистик
· Вспомогательные показатели (p-value, ...)
Показатели качества уравнения в целом
· R2
· Скорректированный R2
· Значения F-статистики
· Сумма квадратов остатков (RSS)
· Стандартная ошибка регрессии (SEE)
152. Для чего используется показатель стандартной ошибки уравнения регрессии?
Стандартная ошибка дает общее представление о степени точности коэффициента регрессии, используется при расчете t-статистики и значений p для параметра.
153. Как рассчитывается показатель стандартной ошибки уравнения регрессии?
![]() для случая парной регрессии , где
для случая парной регрессии , где ![]() - выборочная дисперсия остатков
- выборочная дисперсия остатков
Если у нас регрессия с 2мя независимыми переменными, то используем
![]()
154. Какова связь показателей качества коэффициентов регрессии и показателей качества уравнения в целом в случае множественной регрессии?
В случае множественной регрессии t-тест и F-тест выполняют разные функции: t-тесты проверяют значимость коэффициента при каждой переменной по отдельности, в то время как F-тест проверяет их совместную объясняющую способность.
Вообще говоря, F-статистика будет значимой, если значима по крайней мере одна из t-статистик. Однако в принципе F-статистика может и не быть значимой в этом случае. Пример: Предположим, что вы оценили не имеющую смысла регрессию с 40 объясняющими переменными, каждая из которых не является действительным детерминантом зависимой переменной. В этом случае F-статистика должна оказаться достаточно низкой, чтобы гипотеза Н0 не была отвергнута. Однако если выполнить t-тесты для коэффициентов наклона на 5%-ном уровне, то в среднем можно ожидать, что 2 из 40 переменных будут иметь «значимые» коэффициенты.
В то же время может получиться, что F-статистика будет значимой при незначимости всех t-статистик. Пример: предположим, у вас имеется модель множественной регрессии, которая правильно специфицирована, и коэффициент детерминации высокий. Вероятно, что в этом случае F-статистика высоко значима. Однако если объясняющие переменные сильно коррелированны и модель подвержена сильной мультиколлинеарности, то стандартные ошибки коэффициентов наклона могут оказаться столь велики, что ни одна из t-статистик не будет значима.
155. Каковы особенности анализа коэффициента детерминации в случае множественной регрессии?
Как и в парном регрессионном
анализе, коэффициент детерминации R2 определяет долю
дисперсии у, объясненную регрессией, и эквивалентно определяется как
величина![]() . Этот коэффициент никогда не уменьшается (а
обычно он увеличивается) при добавлении еще одной переменной в уравнение
регрессии, если все ранее включенные объясняющие переменные сохраняются. Если
новая переменная на самом деле не относится к уравнению, то увеличение
коэффициента R2 будет, вероятно, незначительным.
. Этот коэффициент никогда не уменьшается (а
обычно он увеличивается) при добавлении еще одной переменной в уравнение
регрессии, если все ранее включенные объясняющие переменные сохраняются. Если
новая переменная на самом деле не относится к уравнению, то увеличение
коэффициента R2 будет, вероятно, незначительным.
Скорректированный коэффициент R2,
который обычно обозначают ![]() , обеспечивает компенсацию для такого
автоматического сдвига вверх путем наложения «штрафа» за увеличение числа
независимых переменных. Этот коэффициент определяется следующим образом:
, обеспечивает компенсацию для такого
автоматического сдвига вверх путем наложения «штрафа» за увеличение числа
независимых переменных. Этот коэффициент определяется следующим образом: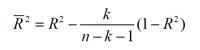 , где k — число независимых переменных. По мере роста k увеличивается отношение k/(п — k— 1) и,
следовательно, возрастает размер корректировки коэффициента R2 в
сторону уменьшения.
, где k — число независимых переменных. По мере роста k увеличивается отношение k/(п — k— 1) и,
следовательно, возрастает размер корректировки коэффициента R2 в
сторону уменьшения.
Можно показать, что добавление новой переменной к регрессии приведет к увеличению R2, если и только если соответствующая r-статистика больше единицы (или меньше —1). Следовательно, увеличение R2 при добавлении новой переменной необязательно означает, что ее коэффициент значимо отличается от нуля. Поэтому отнюдь не следует, как можно было бы предположить, что увеличение R2 означает улучшение спецификации уравнения.
156. Для чего используется скорректированный коэффициент детерминации?
Для наложения «штрафа» за увеличение числа объясняющих переменных, так
как обычный ![]() при увеличении числа переменных всегда
растет.
при увеличении числа переменных всегда
растет.
157. Как рассчитывается скорректированный коэффициент детерминации и какие факторы определяют его значение?
![]() , где
, где
k-1 – число объясняющих переменных.
Как и обычный ![]() , скорректированный зависит от
«объяснённой» суммы квадратов отклонений от выборочного среднего (ESS) и остаточной суммы квадратов (TSS),
т.е. от
, скорректированный зависит от
«объяснённой» суммы квадратов отклонений от выборочного среднего (ESS) и остаточной суммы квадратов (TSS),
т.е. от ![]() ,
, ![]() , Y. Но, в отличие от
, Y. Но, в отличие от ![]() , adjusted
, adjusted ![]() не увеличивается
при добавлении любых объясняющих переменных. Adjusted
не увеличивается
при добавлении любых объясняющих переменных. Adjusted ![]() увеличится только если соотвестсвующая добавленной переменной t-статистика
больше 1 или меньше -1.
увеличится только если соотвестсвующая добавленной переменной t-статистика
больше 1 или меньше -1.
ТЕМА 14. Тесты на значимость уравнения множественной регрессии и его коэффициентов.
158. На основании каких показателей можно судить о качестве регрессионной модели в целом?
При проверке качества модели в первую очередь стоит обращать внимание на то, соответствует ли она логике экономического процесса, т.е. мы должны смотреть, реалистичны ли знаки коэффициентов перед независимыми переменными и реалистична ли их величина.
Традиционно качество регрессии оценивается с
помощью: ![]() , t-статистики
и F-статистики.
, t-статистики
и F-статистики.
Далее – подробный ответ. В принципе, не нужен – как и говорил Черняк. Однако может пригодиться в подготовке, решайте сами. «Ненужное» выделил серым.
R2 (коэффициент детерминации):
Коэффициент детерминации показывает объясняющую способность регрессии.
Формула ![]() =
= 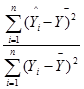 , где
, где
![]() -расчётное (оно же теоретическое и предсказанное) значение
-расчётное (оно же теоретическое и предсказанное) значение
![]() - выборочное среднее.
- выборочное среднее.
Чем выше ![]() ,
тем больше построенная нами линия регрессии соответствует всем наблюдениям.
Поэтому если мы хотим по регрессии строить предсказания (т.е. подставлять значения
независимых переменных и получать точную, правдивую оценку зависимой), нам
необходим высокий
,
тем больше построенная нами линия регрессии соответствует всем наблюдениям.
Поэтому если мы хотим по регрессии строить предсказания (т.е. подставлять значения
независимых переменных и получать точную, правдивую оценку зависимой), нам
необходим высокий ![]() .
.
t-статистика:
t-статистика соизмеряет значение коэффициента с его стандартной ошибкой. Фактически же мы проверяем гипотезу о том, равен нулю коэффициент при рассматриваемой переменной или нет. Т.е:
Ho: коэффициент=0. Если эта гипотеза верна, то коэффициент не значим.
Ha: коэффициент не равен 0. Если эта гипотеза верна, то коэффициент значим.
Выяснить, отвергается нулевая гипотеза или нет, можно 2 способами:
1. Метод критических значений (по таблицам):
a) Находим фактическое значение t (Черняк не говорил формулу, так что она м.б. и не нужна):
t=![]() , где
, где
SE – стандартная ошибка коэффициента.
b) Определяем число степеней свободы
df .=n-k=25-2=23
n – число наблюдений
k – число оцененных параметров
c) Выбираем уровень значимости (т.е. вероятность ошибки): 1% или 5%.
d) Находим критическое значение по таблице:
в таблице выбираем клетку в строке, соответствующей числу степеней свободы и в столбце, соответствующем выбранному уровню значимости.
e) Сравниваем фактическое значение с табличным:
Если t![]() > t
> t![]() , то коэффициент
значим на выбранном уровне значимости (лучше сначала на 1% проверить). Т.е.
нулевая гипотеза отвергается.
, то коэффициент
значим на выбранном уровне значимости (лучше сначала на 1% проверить). Т.е.
нулевая гипотеза отвергается.
Если t![]() < t
< t![]() , то коэффициент не
значим. Нулевая гипотеза не отвергается.
, то коэффициент не
значим. Нулевая гипотеза не отвергается.
2. Метод «p-value» («метод значения вероятности»). Используется при работе в EViews:
p-value = Prob – вероятность того, что случайно (по другой выборке, другим исследователем) будет получен результат лучше, чем у нас (тот, что рассчитан).
Процедура проверки:
a) Сравниваем значение Prob из EViews с 1% (т.е. с 0.01).
b) Если Prob.< 0.01, то коэффициент значим на 1% уровне.
c) Если Prob.> 0.01, тогда проверяем его значимость на 5% (сравниваем с 0.05)
F-статистика:
F-статистика представляет собой отношение объясненной суммы квадратов (в расчете на одну независимую переменную) к остаточной сумме квадратов (в расчете на одну степень свободы).
Фактически проверяем гипотезу:
Но:
все коэффициенты при независимых переменных равны нулю (![]() )
)
На: хотя бы один из них нулю не равен.
Выяснить, отвергается нулевая гипотеза или нет, можно 2 способами:
1. По таблицам:
a) Рассчитываем фактическое по формуле:
F(k-1,n-k)=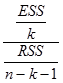 , где
, где
k - число объясняющих переменных.
b) Находим табличное:
· Выбираем уровень значимости α (1% или 5%)
· Вычисляем число степеней свободы: 1 и (n-2).
· По таблицам F-распределения Фишера определяем критическое значение Fα, 1, n-2 (всегда одностороннее)
c) Если Fстатистика(фактическое) > Fα , 1, n-2, то уравнение в целом является значимым при выбранном уровне значимости α .
d) В противном случае уравнение в целом незначимо (на данном уровне α ).
2. В EViews:
Точно так же, как в случае с t-статистикой, сравниваем с Prob.
159. Для чего используется F-критерий при оценке качества уравнения множественной регрессии?
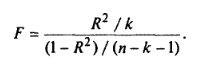
F-статистика используется для анализа дисперсии. После получения F-статистики можно провести F-тест, который определит, действительно ли объясненная сумма квадратов больше той, которая может иметь место случайно. Для этого ищем критическое значение F в таблице Фишера с (k; n-k-1) степенями свободы и сравниваем с F-статистикой. Если расчетное значение больше, чем критическое, то уравнение в целом значимо на том уровне, на котором вы смотрели в таблице.
160. Как рассчитать значение F-критерия для множественной регрессии, исходя из знания сумм квадратов остатков?
При использовании регрессионого анализа для деления дисперсии зависимой переменной
на «объясненную» и «необъясненную» составляющие, можно построить
F-статистику:
![]()
где ESS— объясненная сумма квадратов отклонений;
RSS— остаточная (необъясненная) сумма квадратов;
к — число степеней свободы, использованное на объяснение.
С помощью этой статистики можно выполнить F-тест для определения того, действительно ли объясненная сумма квадратов больше той, которая может иметь место случайно. Для этого нужно найти критический уровень F в колонке, соответствующей к степеням свободы, и в ряду, соответствующем (п-к-1) степеням свободы, в той или иной части табл. А.З. Чаще всего F-тест используется для оценки того, значимо ли объяснение, даваемое уравнением в целом. Кроме того, с помощью F-статистик можно выполнить
ряд дополнительных тестов (Доугерти, стр. 160).
161. Как рассчитать значение F-критерия для множественной регрессии, исходя из знания коэффициента детерминации R2?
![]()
162. Какова особенность расчета числа степеней свободы для F-критерия в множественной регрессии?
![]()
![]()
В данном случае учитываются две степени свободы v1 и v2.
v1 = k
v2 = n – k – 1
k – число объясняющих переменных (без константы)
Fкрит = (уровень значимости; v1; v2)
163. Каков вид F-распределения? Почему обычно используются только односторонние F-критерии?
F-распределение является асимметричным.
Обычно используется односторонние критерии, так как это позволяет спасти значимость коэффициентов регрессии при том же уровне значимости.
 Функция
плотности вероятности F-распределения для степеней свободы a и b приведена на
графике справа.
Функция
плотности вероятности F-распределения для степеней свободы a и b приведена на
графике справа.
В эконометрике количество наблюдений всегда превышает одно, следовательно, график плотности вероятности распределения Фишера имеет вид, как на рисунке обозначено зеленым и фиолетовым.
Односторонний критерий имеет более высокую мощность, чем двухсторонний критерий — при той же вероятности ошибочного отклонения нулевой гипотезы. Это говорит о предпочтительности одностороннего критерия по сравнению с двухсторонним.
164. Каков содержательный смысл отношения Фишера в определении F-критерия?
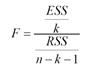 F-статистика представляет
собой отношение объясненной суммы квадратов (в расчете на одну независимую переменную)
к остаточной сумме квадратов (в расчете на одну степень свободы), где k - число
объясняющих переменных. Улучшение уравнение может происходить за счет добавления
переменных, поэтому сумма квадратов остатков – эталонное значение –
распределяется по количеству переменных, и сравниваются значения суммы
квадратов остатков, объясненных регрессией и остаточных.
F-статистика представляет
собой отношение объясненной суммы квадратов (в расчете на одну независимую переменную)
к остаточной сумме квадратов (в расчете на одну степень свободы), где k - число
объясняющих переменных. Улучшение уравнение может происходить за счет добавления
переменных, поэтому сумма квадратов остатков – эталонное значение –
распределяется по количеству переменных, и сравниваются значения суммы
квадратов остатков, объясненных регрессией и остаточных.
165. Каковы общие принципы выбора уровня значимости при использовании F-критерия для оценки качества уравнения в целом?
С одной стороны, большой уровень значимости дает большую уверенность в том, что альтернативная гипотеза значима. Но при этом возрастает риск не отвергнуть ложную нулевую гипотезу (ошибка второго рода). Таким образом, выбор уровня значимости требует компромисса между значимостью и риском ошибки и, следовательно, между вероятностями ошибок первого и второго рода. Обычно гипотезы проверяются на уровне значимости 1% или 5% (тоже самое, что и для уровня значимости при оценки коэффициентов).
166. Для чего используются t-тесты для коэффициентов регрессии и какова интерпретация их результатов?
t-тесты обеспечивают проверку значимости предельного вклада каждой переменной при допущении, что все остальные переменные уже включены в модель.
t-тесты нужны для того, чтобы отвергнуть или не отвергнуть гипотезу о равенстве коэффициента перед переменной нулю. Если мы отвергаем гипотезу, значит, коэффициент значим. Условие того, что оценка регрессии приводит к отказу от нулевой теории H0: β2= β20 (β20принимается равным 0), следующее:
t-крит < 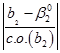
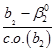 = t-статистика,
причем, т.к. = 0, t-статистика =
= t-статистика,
причем, т.к. = 0, t-статистика = ![]() . t-статистика соизмеряет
значение коэффициента с его стандартной ошибкой
. t-статистика соизмеряет
значение коэффициента с его стандартной ошибкой
Сравнивая значение коэффициента с его стандартной ошибкой, можно судить о значимости коэффициента.
Иначе условие значимости можно записать так: t-крит<|t-статистика|
Однако незначимость коэффициента регрессии не всегда может служить основанием для исключения соответствующей переменной из модели.
167. Какова связь между F-критерием и t-критериями для коэффициентов регрессии? Есть ли связь между соответствующими критическими значениями?
В случае множественного регрессионного анализа. F-статистика = квадрату t-статистики (F = t2).
Между критическими значениями, при любом заданном уровне значимости:
F-крит. = t2-крит. (при двустороннем тесте).
168. Как проверить гипотезу о значимости коэффициента детерминации? В чем смысл такого теста?
F-тест. Это нужно для проверки значимости уравнения в целом.
Иногда, даже если R2 и коэффициент корреляции в точности равны 0, это не значит, что зависимость отсутствует. Зависимость может и присутствовать. Возможно она слабая, но есть. F-тест помогает узнать действительно ли полученное для регрессии значение R2 или нет (отражает существует ли истинная зависимость или нет).
F-тест основан на анализе дисперсии. Дисперсию зависимой переменной можно разложить на «объясненную» и «необъясненную» составляющие дисперсии, используя уравнение:
![]()
Левая часть является общей суммой квадратов (TSS) отклонений зависимой переменной от ее выборочного среднего значения. Первый член в правой части является объясненной суммой квадратов (ESS), а второй член – необъясненной (остаточной) суммой квадратов (RSS):
TSS = ESS + RSS
F-статистика для проверки общего качества регрессии записывается как отношение объясненной суммы квадратов в расчете на одну независимую переменную, деление на остаточную сумму квадратов в расчете на одну степень свободы:
![]()
Где k – число оцениваемых параметров в уравнении регрессии (k-1 – коэффициенты наклона).
После преобразования получаем:
![]()
После вычисления F-критерия по значению R2 вы отыскиваете величину Fкрит – критический уровень F в соответствующей таблице.
Если F > Fкрит, то нулевая гипотеза отклоняется и вывод: имеющееся объяснение поведения величины Y лучше, чем можно было получить чисто случайно. В каждом случае критический уровень зависит от числа независимых переменных (k-1), которое находится в верхней строке таблицы, и от числа степеней свободы (n-k), которое находится в крайнем левом ее столбце.
На практике F-статистика всегда вычисляется вместе с величиной R2. Может возникнуть вопрос, почему нет таблиц значений R2? Ответ: таблица значений F-критерия является полезной для многих видов проверки дисперсии, одним из которых является расчет коэффициента R2.
Более подробно смотрите наш учебник Доугерти (с. 116).
169. Как формулируется нулевая гипотеза при использовании F-теста для оценки качества уравнения в целом?
Все коэффициенты наклона в уравнении одновременно равны нулю.
170. Почему суммы квадратов остатков, как правило, не сравнимы, а стандартные ошибки регрессии в определенных случаях сравнимы? В каких?
С RSS не сравнимы из-за разницы
в масштабах линейной и логарифмической моделей.
Стандартные ошибки сравнимы относительно, через t-статистики
– они везде работают (ответ Черняка).
171. Как делается тест на значимость коэффициента множественной регрессии?
Значимость коэффициентов множественной регрессии проверяется по t-критерию Стьюдента.
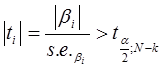 ,
, 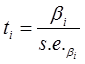 расчетное значение
t-статистики коэффициента bi
расчетное значение
t-статистики коэффициента bi
172. Можно ли считать модель верной, если модель в целом значима, и все ее коэффициенты значимы?
Нет, эконометрика ничего не проверяет, а только проверяет гипотезы с определённой ошибкой. Но такая ситуация – сильный аргумент в пользу верности.
173. Почему t-статистики нельзя использовать для анализа данных по всей изучаемой совокупности?
Потому что t-статистики могут быть использованы только для конкретной выборки.
174. Могут ли существовать несколько «одинаково хороших» множественных регрессий с одной и той же зависимой переменной и разным составом объясняющих переменных?
Если говорить о поверхностных различиях, то – да, например, такое часто наблюдается при замене одной переменной другой, сильно коррелированной с первоначальной. Для окончательного уточнения вида модели тогда придется проводить другие, более специфичные тесты. (например, доход зависит от многих переменных, которые «подменяют» друг друга и сложно оценить вклад каждой)
ТЕМА 15. Мультиколлинеарность.
175. Что такое мультиколлинеарность в эконометрике?
Смысл мультиколлинеарности.
Слово «коллинеарность» описывает линейную связь между двумя независимыми переменными, тогда как «мультиколлинеарность» – между более чем двумя переменными. На практике всегда используется один термин. Термин «мультиколлинеарность» введен Рагнаром Фришем.
Виды мультиколлинеарности
1. Строгая (perfect) мультиколлинеарность – наличие линейной функциональной связи между независимыми переменными (иногда также и зависимой).
2. Нестрогая (imperfect) мультиколлинеарность – наличие сильной линейной корреляционной связи между независимыми переменными (иногда также и зависимой).
176. В чем сущность проблемы мультиколлинеарности?
Корреляционные связи есть всегда. Проблема мультиколлинеарности – проблема силы проявления корреляционных связей.
Однозначных критериев мультиколлинеарности не существует.
Строгая мультиколлинеарность нарушает одно из основных правил Гаусса-Маркова и делает построение регрессии полностью невозможным.
Нестрогая мультиколлинеарность затрудняет работу, но не препятствует получению правильных выводов.
177. Каковы основные причины возникновения мультиколлинеарности?
1. ошибочное включение в уравнение 2х или более линейно зависимых переменных
2. две или более объясняющие переменные, в нормальной ситуации слабо коррелированные, становятся в конкретных условиях выборки сильно коррелированными.
3. в модель включается переменная, сильно коррелирующая с зависимой переменной.
178. Что такое доминантная переменная?
Это такая независимая переменная, включаемая в модель, которая сильно коррелирует с зависимой переменной. Такая переменная «забивает» влияние всех остальных переменных и их влияние становится незначимым.
179. В чем состоит интерпретация метода наименьших квадратов как метода определения вклада факторов?
МНК позволяют оценить вклад каждого фактора по отдельности даже в случае, когда переменные сильно коррелированны. (сильная мультиколлинеарность)
180. Почему мультиколлинеарность может быть охарактеризована в большей степени как проблема выборки, а не генеральной совокупности?
Потому что мультиколлинеарность в большей степени зависит от свойств самой выборки, например, количества наблюдений и величины ошибок при измерении переменных.
Мультиколлинеарность - явление, проявляющееся на уровне выборки:
1. В одной выборке мультиколлинеарность может быть сильной, в другой - слабой
2. Выборочные данные следует всесторонне предварительно исследовать.
3. Полезен расчет выборочных коэффициентов корреляции, ковариационной матрицы и ее определителя.
181. Может ли проявиться мультиколлинеарность при отсутствии явных парных корреляционных зависимостей между переменными?
Может. Так как мультиколлинеарность – ситуация линейной зависимости между объясняющими переменными. Однако вовсе необязательно это зависимость должна быть парной.
182. Каковы основные проявления и последствия мультиколлинеарности в регрессионном анализе?
Вводная информация:
2 вида мультиколлинеарности:
1) Строгая Мультиколлинеарность – наличие линейной функциональной связи между независимыми переменными (иногда также и зависимой)

2) Нестрогая мультиколлинеарность – наличие сильной линейной кореляционой связи между независимыми переменными (иногда также и зависимой)
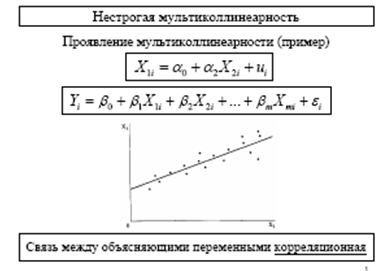
Когда возникает мультиколлинеарность:
1. Ошибочное включение в уравнение двух или более линейно зависимых переменных
2. Две или более объясняющие переменные, в нормальной ситуации слабо коррелированные, становятся в конкретных условиях выборки сильно коррелированными.
3. В модель включается переменная, сильно коррелирующая с зависимой переменной (такая независимая переменная называется доминантной)
Последствия мультиколлинеарности
1. Оценки коэффициентов остаются несмещенными
2. Стандартные ошибки коэффициентов увеличиваются
3. Вычисленные t-статистики занижены.
4. Оценки становится очень чувствительными к изменению спецификации и изменению отдельных наблюдений.
5. Общее качество уравнения, а также оценки переменных, не связанных мультиколлинеарностью, остаются незатронутыми.
6. Чем ближе мультиколлинеарность к совершенной (строгой), тем серьезнее ее последствия.
183. Как влияет мультиколлинеарность на значимость уравнения как целого?
Наличие мультиколлинеарности не говорит о неверной спецификации модели, коэффициенты остаются несмещенными, а стандартные ошибки рассчитываются корректно. Однако из-за увеличения стандартных ошибок возрастает риск того, что уравнение будет ошибочно признано незначимым.
184. Как влияет мультиколлинеарность на значимость отдельных коэффициентов
регрессии?
При наличии мультиколлинеарности стандартные ошибки становятся больше, чем они были бы, если бы мультиколлинеарности не было, что приводит к меньшей надежности полученных оценок.
Другой вариант:
Мультиколлинеарность приводит к увеличению дисперсий оценок коэффициентов, уменьшению значений t-stat. (что приводит к неверным выводам о значимости коэффициента), может выражаться в неверном с точки зрения теории или данных знаке коэффициента (как у нас в семинаре 6). Проявляется в неустойчивости коэффициента и его дисперсии в зависимости от спецификации регрессии, объема выборки (в семинаре 6 коэффициент при располагаемом доходе сильно менялся в зависимости от наших действий и не только из-за смещения). Наличие доминантной переменной (коррелированной с зависимой переменной) делает коэффициенты при остальных объясняющих переменных незначимыми.
185. Могут ли коэффициенты множественной регрессии быть незначимыми, если уравнение в целом значимо?
Таким образом, может проявляться мультиколлинеарность в регрессии с данными объясняющими переменными, даже если модель правильно специфицирована, поскольку происходит занижение t-stat, в то время как общая значимость уравнения и значимость некоррелирующих переменных остаются незатронутыми.
186. Могут ли некоторые коэффициенты множественной регрессии быть значимыми, если уравнение в целом незначимо?
Да, могут. Например, при оценивании не имеющей смысла регрессии с 40 объясняющими переменными, каждая из которых не является действительным детерминантом зависимой переменной, F-статистика должна оказаться достаточно низкой, чтобы гипотеза H0 (модель не обладает никакой объясняющей способностью) не была отвергнута. Однако при выполнении t-теста для коэффициентов регрессии на 5%-ном уровне, существует 5%-ная вероятность допустить ошибку I рода (коэффициенты значимы - истинная гипотеза H0 (коэффициент при переменной равен 0) отвергается), поэтому в среднем можно ожидать, что 2 из 40 переменных будут иметь «значимые» коэффициенты.
187. Почему мультиколлинеарность часто вызывает появление «неправильного» знака коэффициента регрессии?
При мультиколлинеарности коэффициенты становятся неустойчивыми, поскольку становится сложно отделить влияние одной переменной от другой переменной. В результате оценки могут перейти через нуль и оказаться по другую сторону от нуля. Если это происходит, возникает неправильный знак коэффициента.
Другой вариант:
Из-за увеличения стандартных ошибок коэффициентов (дисперсии оценок коэффициентов) – оценка сильно отклоняется от теоретического значения. Такое явление часто возникает, когда коэффициенты при переменных положительны в теоретической модели, а корреляция между объясняющими переменными сильнее, чем каждой из объясняющих переменных с зависимой.
188. Как можно обнаружить наличие мультиколлинеарности?
Проблема мультиколлинеарности может возникнуть, когда существует корреляция между объясняющими переменными.
Наиболее характерные признаки мультиколлинеарности:
ü Небольшое изменение исходных данных (например, добавление новых наблюдений) приводит к существенному изменению коэффициентов модели.
ü Оценки имеют большие стандартные ошибки, малую значимость, в то время как модель в целом является значимой и обладает хорошей объясняющей способностью (хорошие значения F-статистики и R2).
ü Оценки коэффициентов имеют неправильные с точки зрения теории (и логики) знаки или неоправданно большие значения. Коэффициенты, которые по логике должны быть значимы, оказываются незначимыми.
189. Что следует предпринять в случае наличия мультиколлинеарности?
· Можно попытаться уменьшить дисперсию случайного члена: если можем найти важную переменную, которая не включена в модель и, следовательно, вносит вклад в значение u, то мы уменьшим теоретическую дисперсию случайного члена, добавив эту переменную в уравнение регрессии.
· Можно увеличить или изменить выборку.
· Еще возможный путь смягчения проблемы мультиколлинеарности состоит в увеличении среднеквадратического отклонения объясняющих переменных (возможно на стадии проектирования опроса – например, привлекать к участию в опросе и бедное, и богатое население).
· На стадии опроса нужно приложит все усилия для получения такой выборки, в которой объясняющие переменные было бы как можно меньше связаны между собой
· Исключить одну из переменных
· Преобразовать мультиколлинеарные переменные:
o Использовать нелинейные формы
o Использовать агрегаты (линейные комбинации нескольких переменных)
o Использовать первые разности вместо самих переменных
· Ничего не делать! (это не шуткаJ)
ТЕМА 16. Спецификация уравнения регрессии. Выбор переменных.
190. Что включает в себя понятие «спецификация уравнения регрессии»?
Смысл понятия «спецификация уравнения регрессии»: это выбор переменных и выбор формы зависимости.
191. Какой смысл вкладывается в понятие «существенной переменной»?
Переменная, которая должна быть в модели согласно правильной теории.
Допустим, исследуем спрос на теплые варежки. То есть зависимая переменная – Q, спрос на теплые варежки.
В природе есть какая-то истинная модель, которая описывает этот спрос.
Например, на этот спрос влияет цена варежек и температура на улице.
Эти две переменные и называются существенными.
Если не включить одну из них в модель, то можно столкнуться с некачественными результатами.
Подробнее об этой проблеме написано в разделах 6.1-6.2 Доугерти.
192. Что означает «правильно специфицированное уравнение регрессии»?
· Правильная функциональная зависимость (вид функции уравнения регрессии должен отражать истинную зависимость между независимой и зависимыми переменными)
· Отсутствие несущественных переменных
· Учет всех существенных переменных
193. Каковы основные последствия невключения в уравнение регрессии существенной переменной?
1. уменьшается возможность правильной оценки и интерпретации уравнения.
2. коэффициенты при оставшихся переменных могут оказаться смещенными
3. их стандартные ошибки, t-статистики и другие показатели качества становятся некорректными и не могут быть использованы для суждения о качестве уравнения.
194. Каков механизм разрушения оценок коэффициентов при неправильной спецификации уравнения регрессии? Какое отношение имеет этот процесс к условиям Гаусса-Маркова?
Последствия невключения в уравнение существенной переменной
1. Уменьшается возможность правильной оценки и интерпретации уравнения
2. Коэффициенты при оставшихся переменных могут оказаться смещенными
3. Их стандартные ошибки, t-статистики и другие показатели качества становятся некорректными и не могут быть использованы для суждения о качестве уравнения
Если объясняющие переменные коррелированы, то нарушается условие некоррелированности случайного члена и объясняющих переменных
Обнаружение коррелированности случайного члена. Типичные условия нарушения условия Гаусса-Маркова: Cov(ui,uj) = 0 i≠j
195. Какова формула, определяющая величину смещения оценки коэффициента регрессии при невключении в него существенной переменной?
Пусть переменная y зависит от двух переменных x1 и x2.
![]()
Выкидываем x2, т.к. не уверены в ее значимости, и оцениваем регрессию без нее.
![]()
Оценка коэффициента b1 во второй регрессии равна b1 +b2 * Cov(x1,x2)/Var(x1) + ошибка выборки. Смещение определяется b2 * Cov(x1,x2)/Var(x1).
196. Какие основные факторы влияют на направление и величину смещения?
На направление смещения влияют знаки b2 и cov(x1; x2). Если одна из них положительна, а другая отрицательна, то уменьшение коэффициента при x1, а если обе отрицательны или положительны, то увеличение коэффициента при x1.
Величина
смещения коэффициента x1 = ![]() .
Следовательно, она зависит от факторов, которые представлены в формуле, т.е. от
коэффициента при b2, ковариации двух независимых переменных, а также
дисперсии x1.
.
Следовательно, она зависит от факторов, которые представлены в формуле, т.е. от
коэффициента при b2, ковариации двух независимых переменных, а также
дисперсии x1.
197. На основании чего можно оценить вклад факторов, влияющих на знак смещения?
 - Ковариация оценивается
по выборке
- Ковариация оценивается
по выборке
- Знак коэффициента отсутствующей переменной предполагается из теории
198. Что вкладывается в термин «несущественная переменная»?
Переменная несущественна, если она не должна быть включена в уравнение (согласно правильной теории), либо включена лишняя переменная в правильное уравнение регрессии. При включении несущественной переменной не теряется возможность правильной оценки и интерпретации уравнения, коэффициенты при прочих переменных остаются несмещенными, стандартные ошибки растут, t-статистики уменьшаются, эффективность оценок падает. Несущественная переменная может быть значимой, уравнение с ней - давать лучшую оценку. Увеличивается риск мультиколлинеарности.
199. Каковы основанные последствия включения в уравнение регрессии несущественной переменной?
· Не теряется возможность правильной оценки и интерпретации уравнения
· Коэффициенты при прочих переменных остаются несмещенными
· Стандартные ошибки растут, t-статистики уменьшаются, эффективность оценок падает
· Несущественная переменная может быть значимой, уравнение с ней давать лучшую оценку
· Увеличивается риск мультиколлинеарности
200. Можно ли из незначимости переменной регрессии сделать вывод о том, что она является несущественной для уравнения?
Нет!
Незначимость коэффициента не означает отсутствие влияние переменной. Причин почему коэффициент незначим может быть множество: выбрана не та связь (например она не линейная, а логарифмическая), сильная мультиколлинеарность в уравнении, гетероскедастичность, исключена важная объясняющая переменная и ввиду этого мы получили смещенную оценку, возможно что сама структура механизма взаимосвязи гораздо сложнее исследуемой нами модели и тд.
Незначимость- это лишь результат теста EViews, однако первичнее экономическая логика. Стоит подумать над обоснованиями и потом решать – принимать данный результат или поискать причины для устранения незначимости, если есть действительно здравая гипотеза о важности исследуемой переменной.
201. Какими причинами может вызываться незначимость коэффициента при переменной в множественном уравнении регрессии?
Это может быть вызвано тем, что объясняющая переменная влияет на зависимую, также наличием мультиколлинеарной связи с другими переменными, а также включение в уравнение регрессии незначимой переменной.
Также неправильной спецификацией модели.
202. Следует ли всегда исключать из уравнения незначимые переменные? Почему да, или почему нет?
Переменная может быть незначимой, но существенной для конкретной модели. Тогда ее нельзя исключать. Исключение незначимой переменной может привести к смещению коэффициентов других переменных модели.
203. Как можно оценить значимость вклада одной переменной, включаемой в регрессионную модель (необходимо знать два метода, основанных соответственно на использовании t-критерия и F-критерия)?
Значимость включаемой переменной измеряется t-статистикой соответствующего коэффициента. (t тест подходит только для оценки включения одного фактора).
Эквивалентный метод – использование F- критерия. Эквивалентность предполагает двухстороннюю альтернативу для t-критерия.
F-тест (универсальный способ, применимый для включения любого числа факторов)
![]()
![]()
или
![]()
Должно быть ![]()
ИТАК: t-статистика при переменной выполняет 2 функции
1) показывает значимость коэффициента
2) показывает, не является ли целесообразным исключить ее из уравнения
Так как t-стат одна, то эти функции совпадают: если переменная значима, ее целесообразно оставить в уравнении (вообще говоря).
204. Как можно оценить значимость вклада одновременно нескольких переменных,
включаемых в регрессионную модель?
Значимость группы переменных не означает значимости каждой из переменных
Значимость включаемой группы переменных измеряется F-тестом
![]()
![]()
![]()
205. Каково соотношение между значимостью вклада группы включаемых переменных и вкладами отдельно каждой из включаемых переменных?
Значимость группы переменных не означает значимости каждой из переменных.
206. Каковы основные критерии для включения в модель регрессии новой переменной?
Причины задуматься о необходимости включения новой переменной (фантазия на тему).
1. Явная заниженность / завышенность оценки уже включенной переменной.
2. Низкий R2.
Основные критерии для включения в модель регрессии новой переменной:
1. Роль переменной в уравнении опирается на прочные теоретические основания
2. Высокие значения t-статистики
3. Исправленный коэффициент детерминации растет при включении переменной
4. Другие коэффициенты испытывают значительное смещение при включении новой переменной
207. Каковы правила для исключения незначимой переменной из уравнения регрессии?
Исключение переменной означает, что ее влияние на новую регрессию будет осуществляться через случайный член. В таком случае возникает угроза значимости модели в целом, теоретическому смыслу знака коэффициента оставшихся переменных. Поэтому исключение незначимой переменной целесообразно, если:
1) Не возникает смещения оценок
2) Оценки коэффициентов и модель, не включающая незначимую переменную, значимы.
3) Существенная переменная не должна быть исключена (существенная – значимая на основании теории)
4) Оценки коэффициентов при переменных после исключения устойчивы (изменяются незначительно).
208. Каковы основные процедуры поиска спецификации уравнения регрессии? В чем заключаются сравнительные достоинства и недостатки этих процедур?
1. Последовательный восходящий поиск
2. Последовательный нисходящий поиск
Обе процедуры приводят к серьезным ошибкам и следует избегать их автоматического применения, либо резко ограничивать объем поиска.
209. Как влияет включение переменной в уравнение множественной регрессии на
коэффициент детерминации R2?
При включении любой переменной он никогда не уменьшается, а обычно растет.
210. Как влияет включение
переменной в уравнение множественной регрессии на скорректированный коэффициент
детерминации ![]() ?
?
Добавление
новой переменной к регрессии приведет к росту ![]() ,
если и только если соответствующая t статистика
больше 1 (или меньше -1). Следовательно рост
,
если и только если соответствующая t статистика
больше 1 (или меньше -1). Следовательно рост ![]() при добавлении новой
переменной необязательно означает, что ее коэффициент значимо отличается от нуля.
при добавлении новой
переменной необязательно означает, что ее коэффициент значимо отличается от нуля.
211. Как влияет включение переменной в уравнение множественной регрессии на
сумму квадратов остатков уравнения?
![]()
Очевидно, что с увеличением объясняющих переменных, сумма квадратов остатков уменьшается.
212. Как влияет включение переменной в уравнение множественной регрессии на значение F-критерия?
F критерий растет, если переменная существенна, и падает, если она несущественная (лишняя)
213. Как влияет исключение переменной из уравнения множественной регрессии на
коэффициент детерминации R2?
Он либо не изменяется, либо падает. Для множественной регрессии коэффициент детерминации является неубывающей функцией числа объясняющих переменных.
214. Как влияет исключение переменной из уравнения множественной регрессии на
скорректированный коэффициент детерминации ![]() ?
?
Очевидно, уменьшает, если переменная была значимой, так как объясняющая способность регрессии падает. Для этого нужно, чтобы соответствующая t-статистика была больше 1 (или меньше -1).
215. Как влияет исключение переменной из уравнения множественной регрессии на
сумму квадратов остатков уравнения?
Она растет.
216. Как влияет исключение переменной из уравнения множественной регрессии на значение F-критерия?
F критерий падает, если переменная существенна, и растет, если она несущественная (лишняя).
Другой ответ:
Если исключаем важную переменную, то оценки коэффициентов становятся смещенными, а F критерий – некорректным.
ТЕМА 17. Замещающие переменные.
217. Что такое замещающая переменная?
Определение. Переменные, которые вводятся в эконометрические модели вместо тех переменных, которые не поддаются измерению, называются замещающими.
Требование. Замещающая переменная должна коррелировать с переменной, которую она замещает.
218. Для чего и в каких случаях следует использовать замещающие переменные?
Некоторые переменные, которые нужно включить в модель, слишком сложно или вообще невозможно измерить. Например, социально-экономическое положение или качество образования. Тогда вместо отсутствующей переменной можно использовать некоторый заменитель (proxy).
Имеются 2 причины для поиска замещающей переменной.
1) Если мы просто пропустим важную переменную, то регрессия может пострадать от смещения оценок и статистическая проверка будет некорректной.
2) Результаты оценивания регрессии с включением замещающей переменной могут дать косвенную информацию о той переменной, которая замещена данной переменной.
219. Каковы правила для выбора замещающей переменной?
Замещающая переменная является идеальной, если имеется точная линейная связь между ней и той переменной, которую она замещает. Соответственно коэф. корреляции между ними должен быть близок к единице.
220. Каково содержание эффекта замещения отсутствующей переменной в эконометрике?
Включение замещающей переменной позволяет правильно оценить роль других факторов, освободив их от функции замещения отсутствующих переменных.
Коэффициенты замещающих переменных не имеют интерпретации, а сами замещающие факторы не могут быть использованы для формирования экономической политики
Коэффициенты при других переменных модели, их стандартные ошибки и t статистики, R2 будут теми же, как если бы использовалась замещенная переменная.
221. Как можно уменьшить негативные последствия отсутствия существенных переменных с помощью замещающих переменных?
Включить в уравнение замещающую переменную. Это позволит правильно оценить роль других факторов, освободит их от функции замещения существующих переменных.
222. Можно ли использовать коэффициент при замещающей переменной для оценки
коэффициента при замещаемой переменной?
Нет. Коэффициенты при замещающей переменной не имеют интерпретации.
ТЕМА 18. Линейные ограничения.
223. Что понимается в эконометрике под линейным ограничением?
Линейным ограничением называется условие линейной зависимости коэффициентов регрессии.
Справедливость гипотезы о наличии линейного ограничения позволяет исключить лишнюю переменную. Проверка проводится по F-критерию или по t-критерию (непосредственно для включаемой переменной).
224. Какие основные виды линейных ограничений вы знаете (можете ли вы привести несколько примеров)?
225. Как можно проверить значимость линейного ограничения на основе знания сумм квадратов остатков модели без ограничения и модели с ограничением?
С помощью критерия F.
RSSR – сумма квадратов остатков с ограничением
RSSU – сумма квадратов остатков без ограничения
![]()
k – число объясняющих переменных в варианте без ограничения
226. Как можно проверить значимость линейного ограничения на основе знания коэффициентов детерминации модели без ограничения и модели с ограничением?
Проверка проводится по F-критерию или по t-критерию (непосредственно для включаемой переменной). Если регрессия без ограничений имеет m объясняющих переменных, то модель с ограничением l = m – 1. Поэтому F-стат имеет вид
![]()
227. Как формулируется нулевая гипотеза при проверке линейного ограничения?
Yi = α + β1 Xi1+ ... +βk Xk1 + ui
Н0: r1 * β1 + ... + rk * βk = q
228. Какое из уравнений регрессии выбирается в случае, если линейное ограничение оказывается незначимым? Почему?
Выбирается уравнение с ограничением как более простое и обеспечивающее более эффективные оценки (с меньшими ошибками). (Немного странно, но так мне ответил Черняк. Просмотрите, кто соображает, если что, отпишитесь мне – Артём).
229. Какое из уравнений регрессии выбирается в случае, если линейное ограничение оказывается значимым? Почему?
Выбирается уравнение с ограничением, так как в этом случае принимается нулевая гипотеза о равенстве нулю всех дополнительных коэффициентов в уравнении без ограничений.
230. Как проверить одновременно несколько линейных ограничений?
Проверка аналогична проверке на добавление переменных. Т.е. есть одно уравнение с ограничением (restricted), и второе без ограничения (unrestricted), где у нас больше переменных. Тогда и проверяется сразу целесообразность добавления сразу нескольких переменных. Проверка проводится по F-критерию или по t-критерию (непосредственно для включаемой переменной).
![]()
![]()
Плюс в программе можно провести тест Вальда, как на последнем семинаре.
231. В каких случаях и как использовать t-тест при проверке линейного ограничения?
ТЕМА 19. Оценивание нелинейных моделей множественной регрессии.
232. Какие основные виды нелинейных зависимостей используются в эконометрических моделях?
Логарифмическая
Полулогарифмическая
Степенная
233. В каких случаях используются полиномиальные формы регрессии? Какие экономические явления можно отобразить с помощью этих форм?
Когда модель в целом представляется линейной по своей природе
(структуре), но включает в себя нелинейные элементы (например, облако
распределения имеет форму параболы). Например, модель вида ![]() в сущности модель линейна, но при ее
оценивании придется возводить независимую переменную в квадрат. Полиномиальные
формы можно использовать для отображения основной тенденции развития
социально-экономических явлений.
в сущности модель линейна, но при ее
оценивании придется возводить независимую переменную в квадрат. Полиномиальные
формы можно использовать для отображения основной тенденции развития
социально-экономических явлений.
234. В чем состоят основные последствия неправильного выбора и использования функциональных форм?
Последствия данной ошибки таковы:
- Оценки могут быть смещенными;
- Ухудшение статистических свойств оценок или других показателей качества уравнения.
Эти последствия связаны с нарушением условий теорема Гаусса-Маркова для отклонений. Прогнозные качества модели с использованием неправильной функциональной формы очень низки.
235. Можно ли сравнивать статистическое качество различных функциональных форм уравнения регрессии?
Коэффициент детерминации (простой и исправленный) для различных функциональных форм несравним. На статистические характеристики уравнений смотреть можно.
236. Как оценить параметры производственной функции Кобба-Дугласа?
С помощью замены переменных.
Y = A Kα Lβ ν
ln Y = ln A + α ln K +β ln L+ ln ν
237. Как интерпретируются параметры производственной функции Кобба-Дугласа?
При увеличении одного их ресурсов (L или K) на 1% выпуск (Y) растет на α процентов (если K увеличился на 1%), или на β процентов (если L увеличился на 1 %).
238. Что означает условие постоянства эффекта масштаба? Как эконометрически может быть проверено это условие?
Условие постоянства масштаба означает, что Y в производственной функции Кобба-Дугласа изменяется в той же пропорции, что и K и L. Эконометрическая проверка:
- приводим уравнение к линейному виду:
![]()
Для функции с постоянной отдачей от масштаба ![]()
тогда: ![]()
239. Каким образом можно оценить параметры функции Кобба-Дугласа с ограничением на эффект масштаба?
Функция
Кобба-Дугласа имеет вид ![]()
Если сумма α+β равна единице — функция с постоянной отдачей от масштаба; если больше или меньше единицы, имеет место положительный или отрицательный эффекты масштаба соответственно.
Для оценки функции Кобба-Дугласа можно использовать метод наименьших квадратов. Её приводят к линейному виду, прологарифмировав обе части уравнения (как было показано в вопросе 109):
![]()
Для функции с постоянной отдачей от масштаба:
![]()
тогда: ![]()
240. Каким образом можно учесть влияние технического прогресса в производственной функции Кобба-Дугласа?
При использовании агрегированных данных невозможно количественно оценить технический прогресс, проще всего включить экспоненциальный временной тренд в
уравнение, записав функцию Кобба—Дугласа в виде: ![]()
t — время; r — темп прироста выпуска благодаря техническому прогрессу.
После
логарифмирования можно оценить коэффициенты: ![]()
(стр.157)
ЧАСТЬ ВТОРАЯ. ПОСТКОНТРОЛЬНАЯ.
Внимание – часть не редактировалась и не просматривалась!
ЛАГОВЫЕ ПЕРЕМЕННЫЕ
241. Что такое лаг и в чем он измеряется?
ЛАГ - запаздывание, экономический показатель, характеризующий временной интервал между двумя взаимосвязанными экономическими явлениями, одно из которых является причиной, а второе - следствием. Лаг измеряется в периодах, которые характеризуются данными переменными.
Лаговая переменная – это переменная, влияние которой характеризуется некоторым запаздыванием.
242. В чем состоит экономический смысл использования лаговых переменных в
моделях регрессии?
Экономический смысл заключается в возможности существовании зависимости между оцениваемой переменной и независимыми переменными более ранних периодов. Например, можно предположить, что на расходы на жилье влияет личный располагаемый доход и индекс реальных цен более ранних периодов:
![]()
243. В каких случаях целесообразно использование лаговых переменных?
Использование лаговых переменных целесообразно, если оцениваемая переменная инерционна и медленно согласуется с изменениями независимых переменных.
244. Как изменяется число степеней свободы уравнения регрессии при использовании лаговых переменных?
Число степеней свободы уменьшается на число периодов запаздывания.
245. Как отражается на характеристиках модели включение дополнительных лаговых переменных?
Включение лаговых переменных приводит к появлению автокорелляции и, соответственно, к смещению оценок.
ФИКТИВНЫЕ ПЕРЕМЕННЫЕ
246. Что такое фиктивная переменная?
Фиктивная переменная – это переменная, вводимая для оценки влияния качественных факторов. Фиктивная переменная может принимать значение только 0 и 1.
247. Что такое «базовая категория»?
Эта категория при которой значения всех фиктивных переменных в уравнении равны нулю. Выбор базовой категории определяется набором проверок гипотез, которые хотелось бы провести.
248. Как определяется фиктивная переменная сдвига?
Фиктивная переменная сдвига просто добавляется к прочим параметрам уравнения:
![]()
249. Что такое структурный сдвиг в регрессионном анализе? (Точно не знаю)
Структурный сдвиг в регрессионном анализа – это различные оценки значений константы в уравнении регрессии для разных категорий, характеризующие значения фиктивными переменными.
250. Как определяется фиктивная переменная сдвига?
Вопрос 248
251. Как определяется фиктивная переменная наклона?
Фиктивная переменная наклона – это произведение фиктивной переменной на переменную наклон которой мы хотим найти. Причем фиктивная переменная наклона является отдельной объясняющей переменной:
![]() , где Dx
– это фиктивная переменная наклона.
, где Dx
– это фиктивная переменная наклона.
252. Как определяется фиктивная переменная взаимодействия?
Фиктивная переменная взаимодействия выражает зависимость между отдельными группами фиктивных переменных и определяется так же, как и фиктивная переменная наклона - произведением двух фиктивных переменных разных групп:
![]() , где UMD
– это фиктивная переменная взаимодействия.
, где UMD
– это фиктивная переменная взаимодействия.
253. Что такое «ловушка фиктивных переменных»?
«Ловушка фиктивных переменных» - это включение в уравнение фиктивной переменной для эталонной категории. Вследствие этого невозможно дать интерпретацию коэффициентам регрессии, так как теперь отсутствует «база».
254. В каком количестве и как нужно ввести фиктивные переменные для выражения
различий внутри группы с несколькими категориями?
Для выражения различий внутри группы с несколькими категориями число вводимых фиктивных переменных равно числу категорий минус один (минус «базовая категория»).
Если, например, 4 категории нужно выбрать базовую категорию 0, тогда фиктивные переменные D1,D2,D3 будут определяться следующим образом:
Категория 0 D1=D2=D3=0,
Категория 1 D1=1 D2=D3=0
Категория 2 D2=1 D1=D3=0
Категория 3 D3=1 D1=D2=0
255. Как ввести фиктивные переменные для нескольких групп, каждой с несколькими категориями?
Если нескольких групп, каждой с несколькими категориями, то в каждой группе фиктивная переменная определяется для каждой категории, кроме эталонной.
Если, например, 2 группы переменных – UM и D и в каждой по 3 категории, то тогда фиктивные переменные будут определяться следующим образом:
|
UM\D |
Категория 0 |
Категория 1 |
Категория 2 |
|
Категория 0 |
UM1=UM2=0 D1=D2=0 базовая кат. |
UM1=UM2=0 D1=1 D2=0 |
UM1=UM2=0 D2=1 D1=0 |
|
Категория 1 |
UM1=1 UM2=0 D1=D2=0 |
UM1=1 UM2=0 D1=1 D2=0 |
UM1=1 UM2=0 D2=1 D1=0 |
|
Категория 2 |
UM2=1 UM1=0 D1=D2=0 |
UM2=1 UM1=0 D1=1 D2=0 |
UM2=1 UM1=0 D2=1 D1=0 |
256. Как интерпретируется константа при использовании фиктивных переменных
сдвига?
Константа – это оценка базового значения постоянного члена в уравнении регрессии, а коэффициенты при фиктивных переменных служат оценками приращения постоянного члена по сравнению с этим базовым уровнем.
257. Как интерпретируется константа при использовании фиктивных переменных
сдвига и наклона?
y = a + s*f1 + b1*x + t*f2, где f2=f1*x
Константа показывает величину смещения графика регрессии при х равном «0»: одну величину (a), когда фиктивная переменная (f1) принимает значение «0»; другую (a+s) – когда фиктивная переменная (f1) принимает значение «1».
Фиктивная переменная сдвига (какое бы значение она не принимала) не влияет на величину константы.
(др.вариант: константа показывает величину смещения графика регрессии для различных категорий качественной характеристики при х равном «0»).
258. Как интерпретируется коэффициент при фиктивной переменной сдвига?
Он показывает величину (s), на которую изменяется константа (a) в уравнении ререссии, если фиктивная переменная сдвига (f1) принимает значение «1».
259. Как интерпретируется коэффициент при фиктивной переменной наклона?
Он показывает величину (t), на которую изменяется коэффициент наклона (b1) в уравнении регрессии, если фиктивная переменная наклона (f2) принимает ненулевое значение.
(?)260. Как интерпретируется коэффициент при фиктивной переменной взаимодействия?
Возможно – аналогично 259, т.к. ф.п. взаимодействия также будет стоять при х.
Он показывает величину (t), на которую изменяется коэффициент наклона (b1) в уравнении регрессии, если фиктивная переменная взаимодействия (f2) принимает ненулевое значение.
261. Как определяется значимость коэффициента при фиктивной переменной?
С помощью t-теста:
Сравниваем t-статистику фиктивной переменной с t крит. (d.f.; двусторон.тест; уровень значимости). Если больше - значит отвергаем нулевую гипотезу о незначимости различий «у» по различным категориям качественной характеристики.
262. Как определяется значимость одновременно группы фиктивных переменных
сдвига и наклона?
С помощью F-теста:
Нулевая гипотеза (Но): коэффициенты при обеих фиктивных переменных равны 0.
F (k; d.f в уравнении с фикт.пер.) =
[(RSS без ф.п. – RSS с ф.п.)/k] / [RSS с ф.п./d.f. в ур.с ф.п.]
где k - число фиктивных переменных, совокупную значимость которых оцениваем.
Сравниваем с F крит. (k;d.f.;уров.знач-ти). Если больше - значит отвергаем Но.
263. Как определяется значимость одновременно нескольких фиктивных переменных
сдвига?
С помощью F-теста:
Но – все коэффициенты при этих нескольких фикт. переменных равны 0.
Расчет: полностью аналогично вопросу 262.
(?)264. Почему использование фиктивных переменных эквивалентно расчету регрессии на
отдельных частях выборки?
Фиктивная переменная строго принимает одно из 2-ух значений: 0 или 1.Следов-но, автоматически обеспечивается селекция выборки. Базовые коэф-ты рассчитываются так чтобы min-ть RSS для эталонной категории; а коэф-ты при фиктивных переменных – так чтобы min-ть RSS для другой категории. Результат будет в итоге такой же как и в случае оценки отдельных выборок.
265. В чем состоит тест Чоу для обнаружения структурного сдвига?
Тест Чоу = F-тест на значимость улучшения качества уравнения после разделения выборки. Для случая 2-х подвыборок (каждая обладает определенной кач-й хар-кой):
F = [(RSSвся выборка – RSSподвыборка1 – RSSподвыборка2)/k] / [(RSSподвыборка1 + RSSподвыборка2)/n-2k]
k – число использованных степеней свободы (т.е. число оцениваемых параметров)
n-2k – число степеней свободы после разделения выборки
Сравниваем с F крит. (k; n-2k; ур.знач-ти). Если F больше крит-й то Но о незначимости разбиения выборки отвергается.
266. Какую статистику использует тест Чоу? Как определяется число степеней свободы
для этой статистики?
1) F-статистику. 2) В тесте Чоу k и n-2k степени свободы. k - число использованных степеней свободы (в регрессии для всей выборки d.f. = n-k; когда выборку разбили d.f. в сумме по 2-ум подвыборкам = n-2k. Разница м/д ними и есть k); n-2k – число степеней свободы после разделения выборки (где n – объем выборки, k – число оцениваемых параметров).
267. Какому тесту эквивалентно использование теста Чоу?
F-тесту объясняющей способности совокупности фиктивных переменных.
(при условии что включен полный набор фиктивных переменных для качественных характеристик модели)
268. Почему введение фиктивных переменных является предпочтительным по
сравнению с использованием теста Чоу?
Метод фиктивных переменных более информативен: 1) показывает как различаются функции для разных категорий в случае наличия таких различий; 2) дает возможность выполнить t-тесты для отдельных коэф-тов фиктивных переменных.
ВРЕМЕННЫЕ РЯДЫ: СТАЦИОНАРНОСТЬ
269. Что означает, что временной ряд является стационарным?
Это означает, что теоретическое математическое ожидание и теоретическая дисперсия такого ряда не зависят от времени, а также если теоретическая ковариация между его значениями в моменты времени t и t+s зависит от s, но не от времени.
Пример такого ряда: процесс автокорреляции первого порядка AR (1)
Xt = β2*Xt-1 + εt (при -1<β2<1)
270. Какие основные виды нестационарности могут наблюдаться во временном ряде?
1) Случайное блуждание (β2=1):
a) частный случай (без константы): Xt = Xt-1 + εt
б) случайное блуждание с дрейфом: Xt = β1 + Xt-1 + εt
2) Детерминированный тренд (это ряд, включающий временной тренд):
Xt = β1 + β2*t + εt
271. Почему ряд, обладающий трендом, не является стационарным?
Потому что математическое ожидание такого ряда будет зависеть от переменной времени:
матем.ожид-е Xt в момент времени t будет равно β1 + β2*t, т.е. зависеть от t.
272. Каковы правила использования теста Дики-Фуллера для проверки временного ряда
на стационарность?
Стандартный тест ДФ основан на модели: Xt = β1 + β2*Xt-1 + γ*t + εt (проверяется стационарность именно этой модели)
Чтобы это сделать делается преобразование:
∆Xt = β1 + (β2-1)*Xt-1 + γ*t + εt
Но: нестационарность временного ряда. Возможны 2 ее варианта: 1) Но: β2-1 (ряд Xt является случайным блужданием, но при этом стационареным в разностях); 2) Но: γ = 0 (Xt является детерминированным трендом, при этом присутствует трендовая стационарность)
Рассчитываются соответствующие t статистики. Критические значения t стат-к для теста ДФ имеет нестандартное распределение. Есть таблица критических значений, предложенная МакКинноном и Дэвидсоном.
Если t > tcrit то гипотеза нестационарности ряда отвергается.
(?)273. Что является нулевой гипотезой при применении теста Дики-Фуллера?
Но: нестационарность временного ряда. Возможны 2 ее варианта: 1) Но: β2-1 (ряд Xt является случайным блужданием, но при этом стационареным в разностях); 2) Но: γ = 0 (Xt является детерминированным трендом, при этом присутствует трендовая стационарность)
(?)274. Какие табличные значения использует тест Дики-Фуллера?
Таблица критических значений для больших выборок МакКиннона и Дэвидсона.
275. Что делать, если временной ряд не обладает стационарностью?
Нужно найти такую модель, которая позволяла бы предотвратить оценивание кажущихся зависимостей. Возможно три варианта:
1. Устранение тренда переменных (включение времени как регрессора в модель)
2. Вычисление разностей (первые разности – прирост, вторые – изменение приростов) Главный недостаток метода – это препятствует вычислению долговременных зависимостей
3. Построение моделей с коррекцией ошибок
276. Как временной ряд может быть «очищен» от временного тренда?
Посредством включения времени как регрессора в модель (метод не подходит, если переменные стационарны в разностях, например процесс случайных блужданий)
АВТОКОРРЕЛЯЦИЯ
277. Какое из условий Гаусса-Маркова нарушает наличие автокорреляции?
IV. Наблюдаемые значения случайного члена не коррелированны друг с другом.
E(rεiεj )=0(i не равно j)
?278. Какова разница между истинной и ложной автокорреляцией? В чем их сходство?(хз)
Истинная автокорреляция вызывается зависимостью случайного члена от прошлых значений. Истинная не приводит к смещению оценок коэффициентов регрессии.
Ложная – вызывается неправильной спецификацией модели
Средства решения проблемы:
В случае ложной автокорреляции добавить отсутствующую переменную или поменять функциональную форму.
В случае истинной корреляции применить обобщенный метод наим.кв.
279. Что означают термины «автокорреляция первого порядка», «автокорреляция
второго порядка» и т.д.
При автокорреляции первого порядка случайный член ε в модели Yt=β1+β2X1+εt формируется процессом εt=ρεt-1+ut, где ρ – коэффициент автокорреляции 1ого порядка, u – случайный член, не подверженный автокорреляции, -1<ρ<1
При автокорреляции второго порядка случайный член ε в модели Yt=β1+β2X1+εt формируется процессом εt=ρ1εt-1+ ρ2εt-2+ut, где ρ1,ρ2 – коэффициенты автокорреляции, u – случайный член, не подверженный автокорреляции
В автокорреляциях такого типа (авторегрессионного различного порядка) случайный член εt определяется значениями этой же самой величины с запаздыванием, с добавлением нового элемента случайности в виде ut
280. Что такое коэффициент автокорреляции?
Коэффициент автокорреляции отражает, в сущности, обычную корреляцию, вычисляемую между образующими временной ряд текущими и запаздывающими значениями зависимой переменной. Строится по аналогии с линейным коэффициентом корреляции . Этот коэффициент является мерой линейной зависимости между наблюдениями, разделенными определенными временными интервалами, — т. е. мерой линейной связи между смежными наблюдениями.
Порядок коэф автокорреляции показывает зависимость значений автокорреляционной функции от величины лага
?281. Почему коэффициент автокорреляции предполагается находящимся в интервале от минус единицы до плюс единицы?
В автокорреляции 1ого порядка, если в остатках существует полная положительная автокорреляция, то ρ = 1. Если в остатках полная отрицательная автокорреляция, то ρ = – 1. Если автокорреляция остатков отсутствует, то ρ = 0
Если ряд имеет сильную нелинейную тенденцию, коэффициент автокорреляции может приближаться к нулю. Знак его не может служить указанием на наличие возрастающей или убывающей тенденции в уровнях ряда
282. Что такое сезонная автокорреляция?
Сезонная автокорреляция формируется на основе периодически повторяющихся в определенное время года колебаний исследуемого ряда. Характерно для временных рядов с интервалом меньше года
При сезонной автокорреляции случайный член ε в модели Yt=β1+β2X1+εt формируется процессом
εt = ρεt−4 + ut
ε – случайный член рассматриваемого уравнения регрессии; ρ –коэффициент сезонной автокорреляции; u – случайный член, не подверженный автокорреляции.
Т.о. имеет место периодическая сезонная составляющая, которая требует взятия соответствующей сезонной разности.
?283. Какими признаками обладает диаграмма рассеяния при отсутствии
автокорреляции?
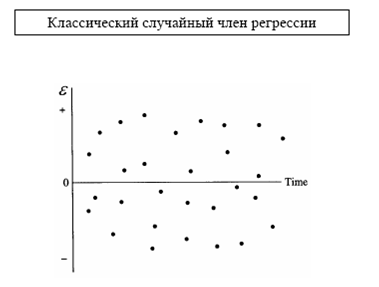
Случайные члены регрессии в разных наблюдениях являются независимыми, могут принимать абсолютно любые отрицательные и положительные значения, отсутствует явный тренд их рассеяния.
284. Что такое положительная автокорреляция?
Положительная автокорреляция - ситуация, когда случайный член регрессии в следующем наблюдении ожидается того же знака, что и случайный член в настоящем наблюдении.
Постоянная направленность воздействия не включенных в уравнение переменных является наиболее частой причиной положительной автокорреляции.
Случайный член формируется в результате взаимодействия невключенных переменных
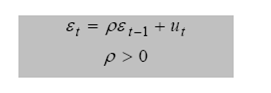
Положительная автокорреляция (наиболее важный для экономики случай) приводит к увеличению дисперсии оценки коэффициентов
?285. Какими признаками обладает диаграмма рассеяния при наличии положительной
автокорреляции?
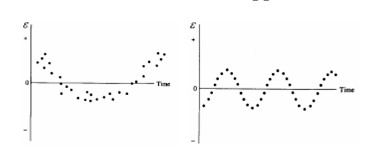
Фактические наблюдения будут в основном сначала находиться выше линии регрессии, затем ниже ее и затем опять выше.
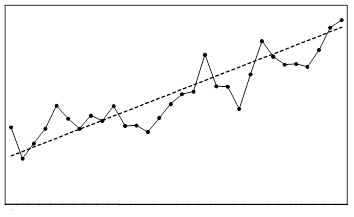 Y
Y=β1+β2X
Y
Y=β1+β2X
β1
X
За положительными отклонениями чаще следуют положительные
Продолжительность и амплитуда каждой положительной и отрицательной последовательности случайны, но в целом будет наблюдаться тенденция к сохранению положительных значений случайного члена после положительных и отрицательных после отрицательных
286. Что такое отрицательная автокорреляция?
Отрицательная автокорреляция - ситуация, когда случайный член регрессии в следующем наблюдении ожидается знака, противоположного знаку случайного члена в настоящем наблюдении
Это означает, что корреляция между последовательными значениями случайного члена отрицательна.
В этом случае, скорее всего, за положительным значением в одном наблюдении идет отрицательное значение в следующем, и наоборот.
Случайный член:
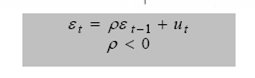
?287. Какими признаками обладает диаграмма рассеяния при наличии отрицательной автокорреляции?
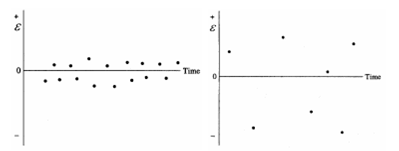
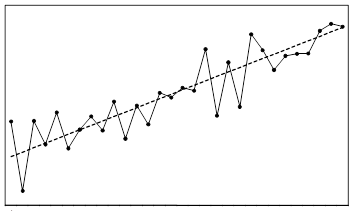 |
Предполагается, что х со временем растет.
Линия, соединяющая последовательные наблюдения друг с другом, будет пересекать линию, показывающую зависимость между у и х чаще, чем , если бы значения случайного члена не зависели друг от друга.
?288. Как проявляется автокорреляция на графике остатков?
?289. Каков механизм возникновения ложной автокорреляции, вызванной ошибочной спецификацией модели регрессии?
Явная автокорреляция может быть вызвана пропуском важной объясняющей
переменной, и положение можно исправить, если эта переменная будет определена
и включена.

?290. Каков механизм возникновения ложной автокорреляции, вызванной неправильным выбором функциональной формы модели?
Самый прямой способ обнаружения автокорреляции, вызванной ошибочной
функциональной спецификацией, заключается в непосредственном рассмотрении
остатков. Это может дать определенное представление о правильной спецификации.
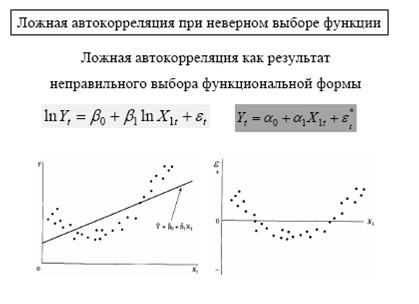
291. Почему проявление автокорреляции наиболее типично для временных рядов?
Автокорреляция обычно встречается только в регрессионном анализе при
использовании данных временных рядов. Во почти всех рядах имеется явная зависимость уровней этого периода от предыдущих им. Например, количество населения за явный год находится в зависимости (при остальных равных условиях) от количестве в предшествующие годы. Случайный член и в уравнении регрессии подвергается воздействию тех переменных, влияющих на зависимую переменную, которые не включены в уравнение регрессии. Если значение и в любом наблюдении должно быть независимым от его значения в предыдущем
наблюдении, то и значение любой переменной, «скрытой» в и, должно быть
некоррелированным с ее значением в предыдущем наблюдении.
292. Каковы основные последствия автокорреляции?
1. Истинная автокорреляция не приводит к смещению оценок коэффициентов регрессии, но оценки перестают быть эффективными
2. Положительная автокорреляция (наиболее важный для экономики случай) приводит к увеличению дисперсии оценки коэффициентов
3. Оценка дисперсии остатков Se2 является смещенной оценкой истинного значения se2 , во многих случаях занижая его.
4. Автокорреляция вызывает занижение оценок стандартных ошибок коэффициентов, что влечет за собой увеличение t-статистик.
5. В силу вышесказанного выводы по оценке качества коэффициентов и модели в целом, возможно, будут неверными. Это приводит к ухудшению прогнозных качеств модели.
293. Каковы основные предпосылки и ограничения использования статистики Дарбина-
Уотсона для обнаружения автокорреляции?
294. Каковы границы изменения статистика Дарбина-Уотсона? Какое значение
статистики Дарбина-Уотсона характеризует отсутствие автокорреляции?
295. Какова связь между статистикой Дарбина-Уотсона и коэффициентом
автокорреляции?
296. Каковы правила использования таблицы статистики Дарбина-Уотсона для
обнаружения положительной автокорреляции?
297. Каковы правила использования таблицы статистики Дарбина-Уотсона для
обнаружения отрицательной автокорреляции?
298. Как следует поступить при попадании статистики Дарбина-Уотсона в «темную
зону»?
299. Какую статистику для обнаружения автокорреляции следует использовать при
наличии лаговой зависимой переменной в качестве объясняющей?
300. Какова формула расчета h-статистики Дарбина? Можно ли использовать
статистику Дарбина-Уотсона в качестве вспомогательного средства для расчета
h-статистики Дарбина?
301. Какое распределение имеет h-статистика Дарбина и при каких предпосылках?
302. Каковы ограничения и условия на использование h-статистики Дарбина?
303. В каких случаях, в регрессии с лаговой зависимой переменной в качестве
объясняющей возможно ограничиться использованием статистики Дарбина-Уотсона?
304. Что такое авторегрессионное преобразование?
Преобразования, уравнения которых в качестве лаговых объясняющих переменных включают значения зависимых переменных
305. Для чего используется авторегрессионное преобразование?
Для устранения автокорреляции
306. В каких случаях авторегрессионное преобразование может оказаться
неэффективным?
307. Как и для чего используется использование лаговых зависимых переменных в
качестве независимых?
Эта процедура используется только для больших выборок
308. Какова практическая реализация обобщенного метода наименьших квадратов?
Если автокорреляция устранена с помощью использования истинного значения р, и сохранения первого наблюдения, то полученная оценка является оценкой по обобщенному методу наименьших квадратов (ОМНК)
309. В каких случаях использование обобщенного метода наименьших квадратов
оказывается особенно эффективным?
При наличии неярко выраженного тренда и высоком значении «ро»
310. Что делать, если использование обобщенного метода наименьших квадратов
оказалось неэффективным?
Использовать обычный метод наименьших квадратов
ГЕТЕРОСКЕДАСТИЧНОСТЬ
311. С нарушением какого из условий Гаусса-Маркова связано наличие
гетероскедастичности?
Нарушение условия, что случайный член гомоскедастичен, т.е. его значение в каждом наблюдении получено из распределения с постоянной теоретической дисперсией. Другими словами, распределение сл.члена для всех наблюдений оказывается постоянным.
σui2= σu2 для всех i. Или E(ui)=σu2. При гетероскедастичности σui2 не одинакова для всех наблюдений.
312. Почему появление гетероскедастичности наиболее типично для пространственных выборок?
Поскольку пространственная выборка дает значения в данный момент времени.
313. В каких случаях можно ожидать проявления гетероскедастичности во временных рядах?
Когда ошибка e в период t более вероятно должна относиться к ошибке в период (t-1)
314. Каков основной механизм возникновения истинной гетероскедастичности? Что
такое фактор пропорциональности?
Истинная гетероскедастичность происходит из-за ошибки, казалось бы корректно специфицированного уравнения:
VAR(εi)=σi2 (i=1,2,…,n)
Если VAR(εi)=σ2 все εi получатся из того же распределения. Возникает гетероскедастичность, если в выборке существует большое несоответствие/расхождение между мин. и макс. значениями зависимых переменных (например, если в одной выборке включены вес баскетболиста и мыши)
Отклонение/колебание ошибок можно отнести к экзогенному параметру Zi. Yi=b0+b1X1i+b2X2i+ εi, где VAR(εi)=σ2Zi2, где Z может как быть, так и не быть частью объясняющего анализа. В данном случае Z – фактор пропорциональности.
315. Каковы возможные механизмы возникновения ложной гетероскедастичности?
Она возникает вследствие неверной спецификации модели, например, за счет упущенных переменных. Это упущение включается в ошибку. Возможно также опускание какого-то члена, что так же приведет к ложной гетероскедастичности.
316. Каковы основные проявления и последствия гетероскедастичности?
Проявления и последствия: Гетероскедастичность влияет на свойства оценок МНК. МНК-оценки не будут BLUE (с минимальным разбросом). Они будут линейными и несмещенными, но не будут иметь мин. дисперсию, т.е. не будут эффективными и наилучшими оценками.
Не
оказывает влияние на оценку коэффициента: E(![]() )=b
)=b
Гетероскедастические ошибки меняют зависимые переменные в том направлении, в котором изменяются независимые переменные.
S.E. будут необъективными, тестовые гипотезы будут несостоятельными. Возможно возникновение ошибки первого рода.
Пусть Y=bX+U
![]() ,
подставляем Y и получаем, что E(
,
подставляем Y и получаем, что E(![]() =B =>
МНК-оценки несмещенные.
=B =>
МНК-оценки несмещенные.
![]() .Гомоскедастичность
предполагает:
.Гомоскедастичность
предполагает:![]() , поэтому
, поэтому 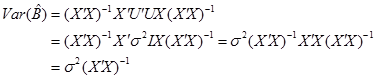
Мы не можем получить![]() ,
если предпосылка о гомоскедастичности не выполняется.
,
если предпосылка о гомоскедастичности не выполняется.
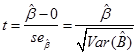 - данный
тест будет ненадежным, т.к. Var(
- данный
тест будет ненадежным, т.к. Var(![]() не будет наилучшим.
не будет наилучшим.
317. Как проявляется гетероскедастичность на графике остатков?
Разброс остатков увеличивается/уменьшается с ростом наблюдений.
318. Каковы основные тесты на гетероскедастичность?
Тесты 2х типов: те, что основаны на априорных предпосылках о природе гетероскедастичности, и те, что опираются на них. Для двух категорий, примером могут быть тест Голдфелда-Квандта и тест Уайта.
319. В чем заключается тест Парка на гетероскедастичность?
Тестируем гетероскедастичность вида: Var(εi)=σ2Z2i
3 шага:
1) получить остатки оцененной регрессии и сохранить их;
2) использовать их для оценки регрессии вида: ln(e2i) =α0+ α1lnZi + ui
3) проверить на значимость ![]() 1 c
помощью t-статистики. Отклонить нулевую гипотезу о
наличии гетероскедастичности (если так оно и будет)
1 c
помощью t-статистики. Отклонить нулевую гипотезу о
наличии гетероскедастичности (если так оно и будет)
320. Каков алгоритм использования теста Голдфелда-Квандта?
Предполагаем, что σui пропорционально значению Xi, σui~N.
1) n наблюдений упорядочиваются по величине X, а затем оцениваются n’ первых и n’ последних наблюдений (средние наблюдения (n-2n’) отбрасываются. Дисперсия u в n’ последних наблюдениях должна быть больше, чем в n’ первых (гетероскедастичность), RSS1>RSS2- нулевая гипотеза
2) Рассчитываем RSS1/RSS2, которое имеет F-распределение с (n’-k) степенями свободы, где k- число параметров. Обычно n’=3/8n
3) сравниваем RSS1/RSS2 с F-критич.
321. Каково правило разделения на подвыборки для использования теста Голдфелда-Квандта?
n наблюдений упорядочиваются по величине X, а затем оцениваются n’ первых и n’ последних наблюдений (средние наблюдения (n-2n’) отбрасываются. Обычно n’=3/8n. Если в модели более одной объясняющей переменной, то наблюдения упорядочиваются по той из них, которая связана с σui.
322. Какое распределение использует тест Голдфелда-Квандта? Как определяются
соответствующие степени свободы?
F-распределение с (n’-k) степенями свободы, где k- число параметров в регрессионном уравнении, n’=3/8n.
323. Для чего используется поправка Уайта на гетероскедастичность при вычислении
регрессии?
Корректировака Уайта добавляет в b характеристику устроенных ошибок (сумма произвед. ошибок), чтобы либо сгладить, либо устранить гетероскедастичность.
324. В чем состоит тест Уайта на гетероскедастичность?
Т.к. σui2 в i-м наблюдении неизвестна, то в качестве замещающей переменной используется квадрат отклонения для этого наблюдения.
1)Оценивается регрессия квадратов отклонений на объясняющие переменные модели, их квадраты и их попарные произведения (исключаются все повторяющиеся переменные). 2)nR2- тестовая статистика (R2-коэфф. детерминации).
3) nR2 Vs c2критич.(k-1), где k – число оцениваемых параметров. Проверяем верна ли нулевая гипотеза об отсутствии связи между дисперсией сл. члена и объясняющей переменной.
325. В чем различие теста Уайта при использовании перекрестных членов (cross-terms)
и без них?
Когда мы используем перекрестный член, то мы дополнительно оцениваем значимость совместного влияния двух факторов с точки зрения гетероскедастичности. ели без него, то одного фактора.
326. Для чего используется взвешенный метод наименьших квадратов?
Взвешенный метод наименьших квадратов компенсирует нарушение предпосылки гомоскедастичности случайного члена путем взвешивания коэффициентов. В случае оценки коэффициентов, если величина зависимой переменной соответствует большим колебаниям величины независимой переменной то их взвешивают в меньшей степени, а в тех случаях, когда небольшие колебания, то им (оценкам коэффициентов) придают большие веса.
Иногда взвешенный МНК иногда используется для подгонки, чтобы придать меньшие веса дальним значениям и резким выбросам.
327. В чем заключается взвешенный метод наименьших квадратов?
Взвешиваются переменные, причем в качестве веса выбирается переменная, которая наиболее всего могла повлиять на возникновение гетероскедастичности (получаются и взвешенные коэффициенты). Например, можно взвесить переменные по возрасту. Т.о. выборка как бы сужается, «шумы» как бы затухают (мы получаем средний уровень случайных ошибок).
328. Как интерпретируется регрессия, полученная взвешиванием по определенному
ряду?
329. Почему после проведения взвешивания по какой-либо переменной свободный член уравнения регрессии дает оценку коэффициента в исходной регрессии?
НО ТАК КАК МЫ ДЕЛИЛИ НА фактор, то нужный коэффициент нужно смотреть в том месте, где сейчас константа (так как при делении GDP на GDP как раз получается константа
330. Почему логарифмирование переменных в ряде случаев позволяет сгладить
последствия гетероскедастичности?
Пусть Y=b1xb2v, где v-случайный член, который увеличивает или уменьшает Y в соответствующей случайной пропорции. logy=logb1+b2logX+logv. При логарифмировании переменных, воздействие logv на logy аддитивно, поэтому абсолютная величина воздействия случайного члена не зависит от величины logx. Модель регрессии стала гомоскедастична.
В принципе, логарифмирование приводит к тому, что переменные меньше расходятся.